В прошлый раз мы говорили об основах работы с Kafka-топиками, включая основные операции с ними. Сегодня поговорим про потребительские Kafka, благодаря которым брокер Kafka имеет возможность повышения эффективности распределенной работы при обработке массивов Big Data.
Как работают потребительские группы в Apache Kafka: основы параллельного обращения к топикам
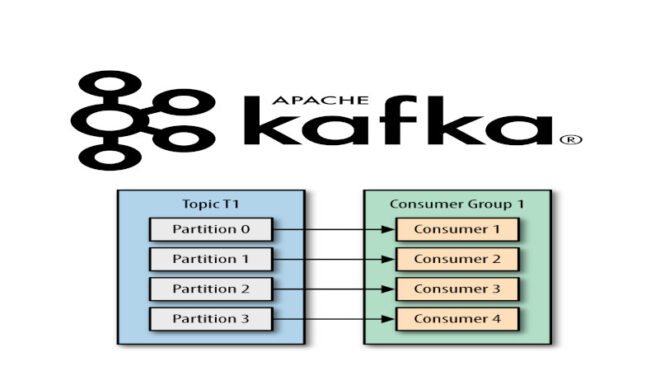
Потребительская группа — это объединение потребителей для многопоточного (многопользовательского) использования топиков Kafka. Потребительские группы в Kafka имеют следующие особенности [1]:
- id — номер группы, который присваивается ей при создании для возможности подключения потребителей, использующих в качестве параметра соединения этот идентификатор (id). Следовательно, для параллельного использования группы, потребители используют один и тот же group.id;
- брокер Kafka назначает разделы топика потребителю в группе таким образом, что каждый раздел потребляется ровно одним потребителем в группе;
- потребители видят сообщение в том порядке, в котором они были сохранены в журнале, независимо от того, в какой момент времени они подключились к группе;
- максимальный параллелизм группы достигается лишь тогда, когда в топике нет разделов.
Особенности работы с потребительскими группами в Kafka: несколько практических примеров
Для работы с потребительскими группами в Kafka используется утилита kafka-consumer-groups.sh. Для того, чтобы вывести список созданных групп, используется параметр --list. Следующая команда отвечает за вывод списка всех групп на сервере [1]:
kafka-consumer-groups.sh --zookeeper zoo1.example.com:2181/kafka-cluster --list
Для того, чтобы добавить описания групп, необходимо заменить параметр --list на --describe и добавить параметр --group, который отвечает за действия над указанной группой [1]:
kafka-consumer-groups.sh --zookeeper zoo1.example.com:2181/kafka-cluster --describe --group testgroup
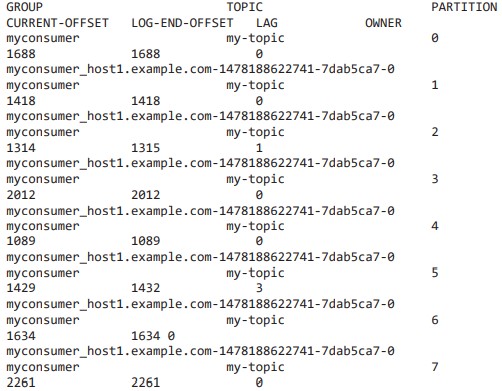
В описании выводится таблица, которая содержит следующие элементы группы:
- GROUP — название группы потребителей;
- TOPIC — название читаемого топика;
- PARTITITON — идентификатор читаемого раздела;
- CURRENT-OFFSET — последнее смещение, зафиксированное группой потребителей для данного раздела топика. Представляет собой позицию, которую занимает потребитель в разделе;
- LONG-END-OFFSET — текущее максимальное смещение для данного раздела топика из имеющихся в брокере;
- LAG — разница между CURRENT-OFFSET потребителя и LONG-END-OFFSET брокера для данного раздела топика;
- OWNER — член группы потребителей, который в настоящий момент выполняет потребление данного раздела топика. Представляет собой произвольный идентификатор, задаваемый самим членом группы [1].
Для удаления группы используется команда —delete совместно с командой —group, которая в качестве параметра принимает название удаляемой группы:
kafka-consumer-groups.sh --zookeeper zoo1.example.com:2181/kafka-cluster --delete --group testgroup
Таким образом, благодаря поддержке механизма потребительских групп, Kafka имеет возможность повышения эффективности параллельной работы с массивами Big Data. Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800 руб.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

