В прошлый раз мы говорили про особенности работы с автономным потребителем в кластере Kafka. Сегодня поговорим про особенности работы и создания продюсера в брокере Apache Kafka. Читайте далее про продюсер сообщений kafka и особенности его архитектуры, благодаря которой брокер Kafka имеет возможность создания и отправки массивов Big Data сообщений в распределенном Kafka-кластере.
Из чего состоит продюсер Kafka: 3 базовых элемента архитектуры
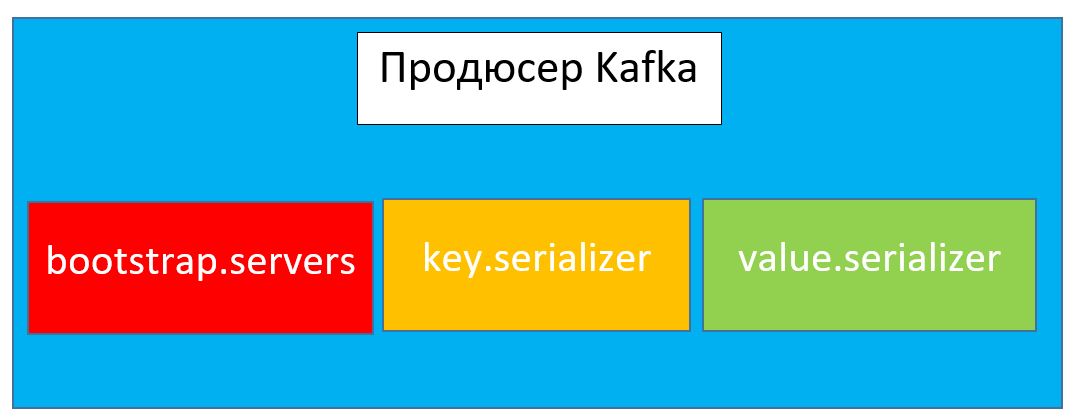
Продюсер Kafka (Kafka producer) — это брокер (или группа брокеров), который отвечает за производство и отправку сообщений Big Data остальным брокерам-получателям (broker consumer) в распределенном Kafka-кластере. Каждый Kafka-продюсер включает в свою архитектуру 3 обязательных элемента:
- bootstrap.servers — список брокеров продюсера для соединения с кластером Kafka. Обычно рекомендуется использовать по меньшей мере два брокера, чтобы продюсер мог подключиться к кластеру при сбое одного из них;
- key.serializer — класс-сариализатор, применяемый для сериализации (преобразования объектов в байтовый массив) ключей записей (сообщений) для отправки брокерам в кластере Kafka. В качестве сериализаторов используются классы StringSerializer (для сериализации строковых объектов) и IntegerSerializer (для сериализации целочсиленных объектов);
- value.serializer — класс-сериализатор, использующийся для сериализации значений (текстовых) записей, генерируемых продюсером для отправки брокерам в распределенном кластере.
Как работает продюсер в брокере Apache Kafka: несколько практических примеров
Для того, чтобы создать Kafka-продюсер, необходимо в первую очередь задать базовую конфигурацию в виде коллекции свойств, в которую входят вышеописанные элементы архитектуры. За создание коллекции свойств продюсера Kafka отвечает класс Properties. Следующий код на языке Java отвечает за создание базовой конфигурации Kafka-продюсера [1]:
//коллекция свойств продюсера
private Properties kafkaProps = new Properties();
//заполнение коллекции
kafkaProps.put("bootstrap.servers", "broker1:9092,broker2:9092");
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
За создание продюсера в Kafka отвечает класс KafkaProducer, в конструктор которого передается объект коллекции свойств Properties. Следующий код на языке Java отвечает за создание Kafka-продюсера [1]:
producer = new KafkaProducer<String, String>(kafkaProps);
После создания продюсера можно приступать к отправке сообщений. За генерацию сообщений отвечает класс ProducerRecord. После генерации записей сообщений (ключ сообщения генерируется автоматически) их можно отправлять в кластер Kafka с помощью метода send(). Следующий код на языке Java отвечает за генерацию и отправку сообщений Kafka-продюсером [1]:
//генерация сообщений
ProducerRecord<String, String> record =
new ProducerRecord<>("CustomerCountry", "Precision Products",
"France");
try {
//отправка сообщений в кластер Kafka
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
Таким образом, благодаря отказоустойчивой архитектуре механизма Kafka-продюсера, брокер Kafka имеет возможность генерировать и рассылать массивы записей Big Data в кластер с весьма высокой степенью надежности. Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений. В следующей статье мы поговорим про виды отправок сообщений в Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

