В прошлый раз мы говорили про цикл опроса в Big Data брокере Apache Kafka. Сегодня поговорим про механизм получения записей с заданными смещениями в Kafka. Читайте далее про механизм заданных смещений, благодаря которому брокеры Kafka могут получать любые необходимые данные из топиков независимо от того, в какой момент времени они появились.
Как работает механизм заданных смещений в Apache Kafka: особенности получения Big Data
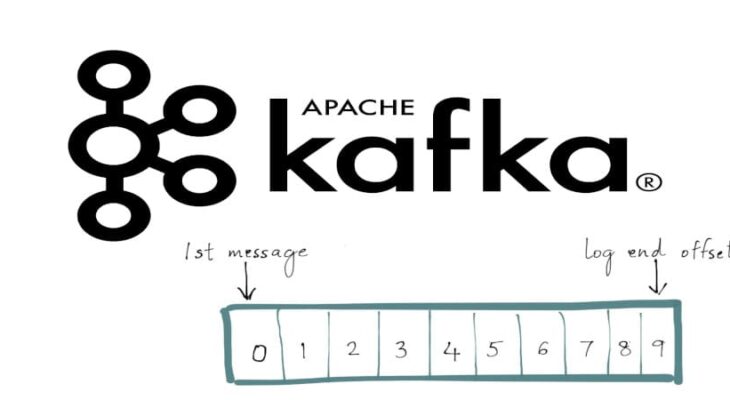
Заданное смещение (current offset) в Kafka — это порядковый номер записи (индекс), который указывается для получения конкретной записи в данный момент времени независимо от того, когда она была создана. Заданные пользователем смещения позволяют переходить к конкретной записи минуя все остальные. Брокер Kafka устроен таким образом, что каждой записи при создании присваивается порядковый номер, на который указывает курсор (метка, которая перемещается при обращении или создании записи). Как только пользователь обращается к конкретной записи, указывая соответствующий индекс, курсор перемещается в данном направлении и фиксируется на заданном элементе (записи) [1].

Работа с заданными смещениями: несколько практических примеров
Для того, чтобы обеспечить возможность получения конкретных записей, можно записывать все смещения и соответствующие им записи в отдельную коллекцию (массив). Для этого необходимо каждый раз при обращении к серверу Kafka создавать экземпляр класса TopicPartition, помещая в него значение (value) записи, а также всю информацию о ее хранении (топик, раздел, смещение). Следующий код на языке Java отвечает за обращение к серверу и заполнение коллекции информацией о каждой полученной от сервера записи [1]:
while (true) { ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
currentOffsets.put(new TopicPartition(record.topic(),
record.partition()),
record.offset());
processRecord(record);
storeRecordInDB(record);
consumer.commitAsync(currentOffsets); } }
Однако стоит отметить, что данный способ не гарантирует корректной работы при аварийном сбое приложения, так как при каждом сбое все обращения к серверу будут инициироваться заново, и при повторном заполнении коллекции в ней появятся дубликаты. Для того, чтобы гарантировать корректное обращение к записям по заданным смещениям во время сбоя, необходимо предусмотреть возможность перебалансировки (передача раздела от неактивного подписчика активному) и каждый раз, когда она происходит, заново выполнять поиск заданного смещения с помощью метода seek() [1]:
public class SaveOffsetsOnRebalance implements
ConsumerRebalanceListener {
public void onPartitionsRevoked (Collection<TopicPartition>
partitions) {
commitDBTransaction();
}
public void onPartitionsAssigned( Collection<TopicPartition>
partitions) {
for(TopicPartition partition: partitions)
consumer.seek(partition, getOffsetFromDB(partition));
}
}
}
Таким образом, благодаря механизму заданных смещений, брокер Apache Kafka гарантирует возможность долгосрочного хранения и получения записей Big Data с необходимой позиции независимо от того, в какой момент времени они были сформированы. Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений. В следующей статье мы поговорим про десериализаторы в Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

