В прошлой статье мы говорили о преимуществах Apache Kafka. Сегодня рассмотрим, какие компоненты входят структуру этой стриминговой платформы, благодаря чему Kafka является лучшим брокером сообщений в мире Big Data. Читайте далее про архитектуру кластера Кафка, которая делает ее таким мощным средством хранения и обмена большими массивами данных.
Главные компоненты кластера Apache Kafka
Прежде всего отметим, что Apache Kafka – это не просто брокер сообщений, а целая стриминговая платформа, на базе которой может быть построена целая корпоративная инфраструктура анализа и обработки Big Data. В этой статье мы разберем ее ключевые составляющие с точки зрения администратора кластера. Итак, компоненты архитектуры Apache Kafka тесно связаны друг с другом: каждый из них выполняет определенную задачу так, чтобы обеспечить других необходимым пакетом метаданных для их дальнейшей работы. Итак, структуру кластера Kafka формируют следующие компоненты:
- служба ZooKeeper;
- распределенный сервер Kafka.
Как работает каждый из вышеперечисленных компонентов мы подробнее рассмотрим далее.
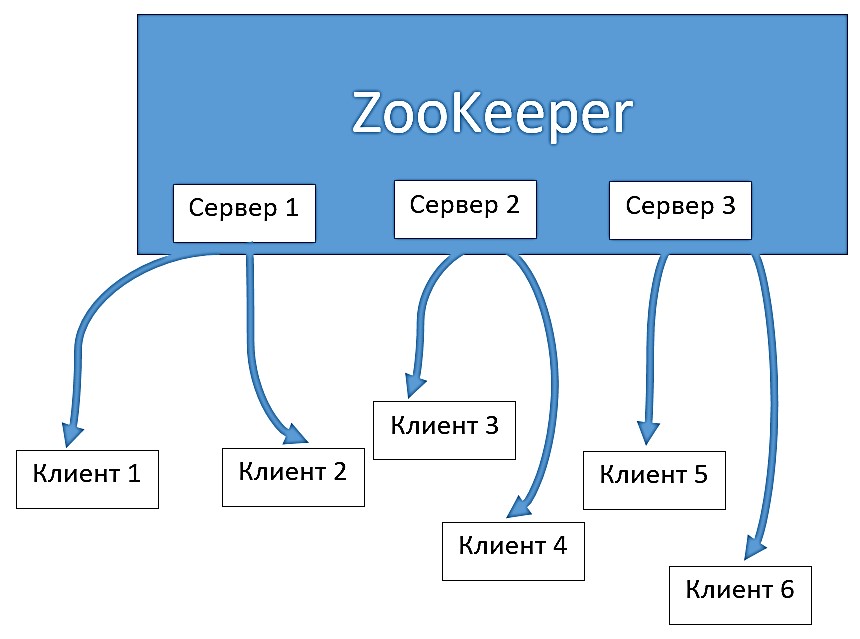
Служба ZooKeeper
Apache ZooKeeper – это распределенная служба для хранения информации о конфигурации основного сервера приложений. ZooKeeper также выполняет функцию управления реакцией сервера на реакцию клиента. Таким образом, каждый клиент посылает сообщение серверу, который находится под управлением ZooKeeper, давая последнему понять, что клиент жив (alive). В ответ на это ZooKeeper генерирует ответ-подтверждение на сервер для дальнейших действий с клиентом. Если так произошло, что клиент не отвечает, ZooKeeper ждет некоторое время (timeout). По истечению тайм-аута ZooKeeper дает статус «неактивен» клиенту и, таким образом, обмен данными с этим клиентом прекращается.
Для того, чтобы настроить ZooKeeper, необходимо выполнить следующие действия:
- загрузить ZooKeeper с официального сайта https://zookeeper.apache.org/;
- в загруженной папке найти папку «conf» и сделать копию файла «zoo_sample.cfg»;
- название копии изменить на «zoo.cfg», открыть ее и в строчке «dataDir=/tmp/zookeeper» прописать полный путь к загруженной папке ZooKeeper (например, dataDir=C:\ZooKeeper\apache-zookeeper-3.6.2-bin)
- добавить переменную среды ZOOKEEPER_HOME и в значении указать путь к папке ZooKeeper (например, ZOOKEEPER_HOME = C:\ZooKeeper\apache-zookeeper-3.6.2-bin)
- в системную переменную Path добавить запись «%ZOOKEEPER_HOME%\bin»
- запустить службу ZooKeeper через командную строку командой
zkserver.
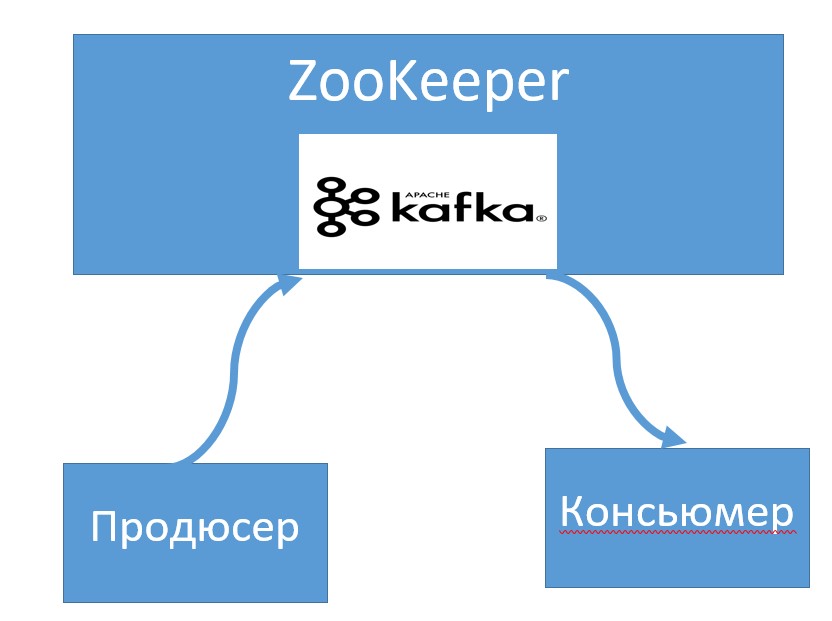
Распределенный сервер Kafka
Распределенный сервер Kafka – это система, которая способна работать, получать и рассылать сообщения на различных узлах (брокерах) кластера. Данные о конфигурации Kafka-сервера хранит служба ZooKeeper.
Сам же сервер хранит информацию о топиках (topics), подписчиках (consumer) и издателях (producer). Сервер также отвечает за рассылку и хранение сообщений. По умолчанию, сообщение хранится на сервере 7 дней и затем удаляется. Для того, чтобы запустить Kafka-сервер необходимо выполнить следующие действия:
- скачать бинарный архив с официального сайта apache.org/downloads;
- в загруженной папке найти папку «config», открыть в ней файл с названием «server.properties» и в строке «log.dirs= /tmp/kafka-logs» указать путь для сохранения логов (например, log.dirs=c:/kafka/kafka-logs);
- в этой же папке редактировать файл с названием «zookeeper.properties»: в строке «dataDir=/tmp/zookeeper» поменять значение на «dataDir=c:/kafka/zookeeper-data».
Таким образом, были произведены базовые настройки сервера. Однако, сервер кафки не будет работать, если не запущена служба ZooKeeper. Для того, чтобы одновременно запустить ее с сервером, можно создать файл с расширением .bat и прописать в него следующие команды:
start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties timeout 10 start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.properties
Таким образом, архитектура Kafka обеспечивает отказоустойчивость и надежность этой Big Data системы, делая ее полезным средством для каждого специалиста в области анализа и обработки больших данных, от Data Scientist’а до разработчика распределенных приложений. В следующей статье мы расскажем про внутреннее устройство брокера Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники

