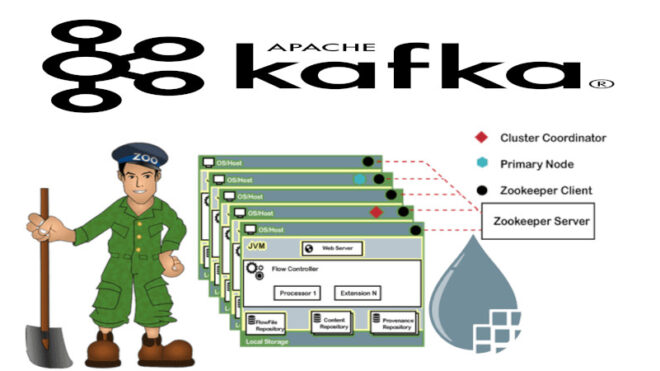
Apache Kafka — это мощная и масштабируемая платформа для обработки и передачи данных в реальном времени. Однако для обеспечения надежности и управления состоянием брокеров Kafka требуется координирующая система. Именно здесь вступает в игру Apache ZooKeeper — высокопроизводительная служба координации для распределенных приложений. Зукипер — это распределенная служба управления конфигурациями, названиями, предоставления служб и синхронизации для распределенных приложений. Она предоставляет простой и надежный способ для приложений взаимодействовать с координационной информацией, такой как конфигурация, статус и другие метаданные.
Особенности работы ZooKeeper: несколько практических примеров
ZooKeeper играет важную роль в архитектуре брокера Kafka. Его функции включают:
- Хранение метаданных: Зукипер хранит метаданные о брокерах Kafka, разделах, топиках и потребителях. Это позволяет брокерам узнавать о состоянии друг друга и определить, где находятся разделы и топики.
- Лидерство и избрание лидера: В Kafka каждый раздел имеет лидера, который обрабатывает все записи и чтения для этого раздела. ZooKeeper помогает в выборе и управлении лидером раздела в случае сбоев.
- Обнаружение сбоев: Зукипер следит за живостью брокеров Kafka. Если какой-либо брокер выходит из строя, Зукипер обнаруживает это и уведомляет остальные брокеры о сбое.
- Управление конфигурацией: Зукипер хранит конфигурационные параметры, такие как настройки брокеров и топиков. Это позволяет быстро изменять параметры без перезапуска брокеров.
Следующий пример на языке Java отвечает за подключение к Zookeeper:
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
public class ZooKeeperConnector {
private static final String ZOOKEEPER_CONNECT_STRING = "localhost:2181";
private static final int SESSION_TIMEOUT = 5000;
public static void main(String[] args) throws Exception {
// Создание объекта ZooKeeper для подключения к ZooKeeper-серверу
ZooKeeper zooKeeper = new ZooKeeper(ZOOKEEPER_CONNECT_STRING, SESSION_TIMEOUT, event -> {
if (event.getState() == Watcher.Event.KeeperState.SyncConnected) {
System.out.println("Connected to ZooKeeper");
}
});
// Ожидание, пока подключение будет установлено
while (zooKeeper.getState() != ZooKeeper.States.CONNECTED) {
Thread.sleep(100);
}
// Теперь можно выполнять операции с ZooKeeper
}
}
В этом примере используется библиотека ZooKeeper для создания объекта ZooKeeper, который устанавливает соединение с сервером ZooKeeper. Мы передаем строку ZOOKEEPER_CONNECT_STRING, содержащую адрес и порт сервера ZooKeeper, а также SESSION_TIMEOUT, который указывает максимальное время ожидания для установки подключения. Затем мы передаем обработчик событий (Watcher), который будет вызван при изменении состояния подключения. В данном случае, при установке синхронного подключения, выводится сообщение «Connected to ZooKeeper». Мы также добавляем цикл, чтобы дождаться установки подключения перед выполнением дальнейших операций.
Таким образом, Apache ZooKeeper играет критическую роль в архитектуре брокера Kafka, обеспечивая координацию, управление конфигурацией и обнаружение сбоев. Это позволяет системе Kafka обеспечивать высокую доступность, надежность и масштабируемость при обработке данных в реальном времени.
Это делает Apache Kafka надежным и универсальным средством для хранения и обмена большими потоками данных, что активно применяется в задачах Data Science и разработке распределенных приложений.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:

