В прошлый раз мы говорили про управление разделами в брокере Kafka. Сегодня поговорим про пользовательское секционирование в распределенной среде Kafka. Читайте далее про механизм пользовательского секционирования, который позволяет более эффективно распределять Big Data по разделам Kafka-топиков.
Пользовательское секционирование в распределенной среде Kafka
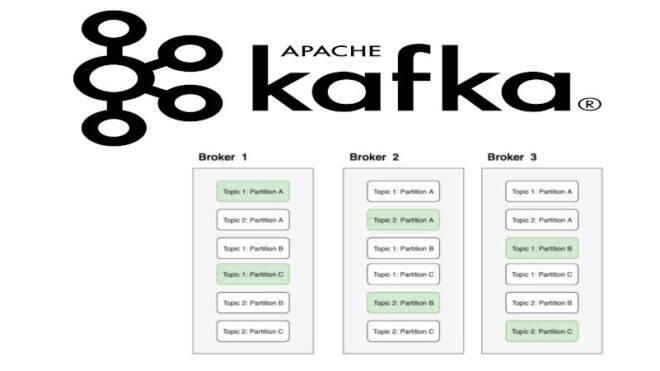
Секционирование в Kafka — это распределение данных по разделам Kafka-топика. Раздел — это последовательность Big Data сообщений топика, которые упорядочены в порядке поступления. По умолчанию, Kafka самостоятельно распределяет данные по разделам. Однако бывают случаи, когда под записи с определенным ключом требуется специальный раздел, который будет содержать записи только необходимого заданного ключа. С этой целью выполняется пользовательское секционирование, которое предполагает выделение раздела под указанный ключ. Таким образом, записи указанного ключа будут содержаться только в специальном (пользовательском) разделе [1].
Создание пользовательского разделителя: несколько практических примеров
Для того, чтобы создать пользовательский разделитель, необходимо использовать JAVA-интерфейс Partitioner, который включает методы configure(), partition() и close() [1]:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.record.InvalidRecordException;
import org.apache.kafka.common.utils.Utils;
public class CustomPartitioner implements Partitioner {
}
Для того, чтобы поместить необходимую запись в специальный раздел, необходимо переопределить метод partition() нашего класса CustomPartition [1]:
public class CustomPartitioner implements Partitioner {
public void configure(Map<String, ?> configs) {}
@Override
public int partition(String topic, Object key, byte[] key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){
//информация о разделе из необходимого топика
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
//общее количество разделов
int numPartitions = partitions.size();
if(key == null){
//исключение при указании нестроковых ключей
throw new InvalidRecordException("We expect all messages to have customer name as key...");
}else{
if(((String)key).equals("custom")){
//запись с заданным ключом попадает в последний раздел, который является специальным
return numPartitions - 1;
}else{
//остальные записи распределяются по другим разделам
return (Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1));
}
}
}
@Override
public void close(){
}
}
}
Таким образом, благодаря пользовательскому секционированию, Kafka обеспечивает разработчика возможностью более эффективно распределять данные с целью избегания замедления их обработки. Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800 руб.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

