В прошлый раз мы говорили про консольного продюсера в Kafka. Сегодня поговорим про механизм управления разделами в распределенной среде брокера Apache Kafka. Читайте далее про управление разделами, которое позволяет оптимизировать потребление ресурсов, а также повысить надежность кластера.
Управление разделами в распределенной среде Apache Kafka
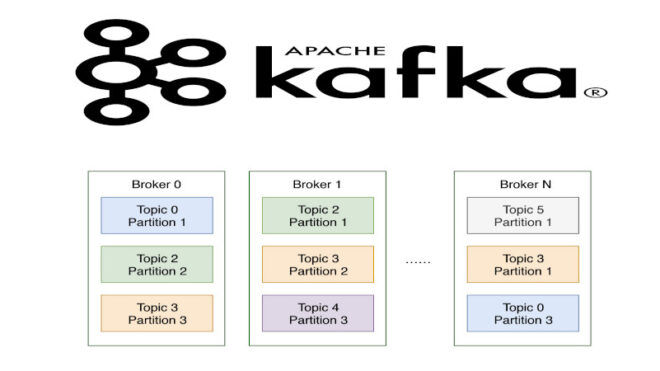
Раздел (partition) — это последовательность сообщений топика, которые упорядочены в порядке поступления. Разделы служат для разделения очередей Big Data с целью защиты топика от переполнения. Каждый раздел подразумевает постоянное копирование данных ч целью избегания их потери. Копирование данных из одного узла на другой называется репликацией. Механизм репликации обеспечивает сохранность данных при сбое или выходе из строя отдельных брокеров в кластере. В Kafka все данные сгруппированы по темам, которые разбиваются на разделы, у каждого из которых могут быть несколько копий (реплик). Эти реплики хранятся на брокерах, каждый из которых может хранить несколько тысяч таких реплик. Таким образом, управление разделами в Kafka происходит путем оптимизации репликации в кластере.
Управление разделами через операции с репликами: несколько практических примеров
Известно, что у разделов может быть несколько реплик (копий самого раздела) для большей надежности. Однако только одна реплика может быть ведущей для раздела. Эта реплика определяется внутри Kafka как первая согласованная в списке реплик, но в случае сбоя и перезапуска брокера не становится ведущей для каких-либо разделов. Чтобы вернуть брокерам статус ведущих, необходимо инициировать выбор предпочтительной ведущей реплики. При этом контроллер кластера самостоятельно выбирает оптимальные ведущие реплики для разделов. Инициировать операцию выбора реплики можно с помощью утилиты kafka-preferred-replica-election.sh (kafka-preferred-replica-election.bat для Windows).
Для примера можно выполнить выбор реплики с заданным числом разделов. Для это в файле JSON зададим количество разделов для каждого из топиков [1]:
{
"partitions": [
{
"partition": 1,
"topic": "foo"
},
{ "partition": 2, "topic": "foobar"
}
]
}
Для того, чтобы инициировать выбор оптимальной реплики, необходимо выполнить следующий набор команд, используя утилиту kafka-preferred-replica-election.sh:
kafka-preferred-replica-election.sh --zookeeper zoo1.example.com:2181/kafka-cluster --path-to-json-file partitions.json
В Kafka также можно изменять коэффициент репликации (общее количество копий). За изменение коэффициента репликации отвечает утилита переназначения разделов kafka-preferred-replica-election.sh (kafka-preferred-replica-election.bat в Windows). Для этого необходимо задать в JSON-файле (файл reassign.json) количество реплик для разделов [1]:
{
"partitions": [
{
"partition": 0,
"replicas": [
1,
2
],
"topic": "my-topic"
}
],
"version": 1
}
После переназначения раздела в данном случае коэффициент репликации будет равен 2. Для переназначения раздела используются следующие команды [1]:
kafka-reassign-partitions.sh --zookeeper zoo1.example.com:2181/kafka-cluster --execute --reassignment-json-file reassign.json
Можно также проверять согласованность реплик с целью контроля и предотвращения сбоев репликации при сбое или останове кластера. Для проверки согласованности реплик используется утилита kafka-replica-verification.sh (kafka-replica-verification.bat для Windows). Она извлекает сообщения реплик из всех реплик заданного набора разделов топика и проверяет наличие всех сообщений во всех репликах. В качестве примера проверим реплики для топиков, название которых начинается с «my-» на брокерах 1 и 2:
kafka-replica-verification.sh --broker-list kafka1.example.com:9092,kafka2.example.com:9092 --topic-white-list 'my-.*'
Таким образом, механизм управления разделами позволяет эффективно использовать ресурсы кластера и избегать потерь данных. Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
5 октября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800 руб.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

