
В прошлый раз мы говорили про систему обмена сообщениями в Apache Kafka. Сегодня рассмотрим базовые принципы устройства клиентской библиотеки Kafka Streams. Читайте далее про архитектуру библиотеки потоков, благодаря которой Apache Kafka позволяет легко разрабатывать распределенные приложения для интерактивного анализа больших данных.
Ключевые принципы работы Kafka Streams
Kafka Streams — это клиентская библиотека Apache Kafka, позволяющая создавать приложения и микросервисы, которые хранятся в Kafka-кластере. Kafka Streams позволяет развертывать стандартные приложения на стороне клиента, используя для этого сервер приложений [1].
Apache Kafka считается лучшем брокером сообщений в мире Big Data. Этим она во многом обязана библиотеке Kafka Streams, благодаря которой Kafka может без проблем работать в любой многопоточной среде. В основе Kafka Streams лежат следующие принципы:
- топология;
- масштабирование.
Топология Kafka Streams
Топология – это конфигурация, установленная в распределенной среде. Обычно эта конфигурация представляет собой граф, вершинам которого соответствуют конечные узлы в кластере. В библиотеке Kafka Streams реализована топология DAG (directed acyclic graph — ориентированный ациклический граф), который представляет собой набор операций и преобразований, через которые проходят все события на пути от входных данных до результатов.
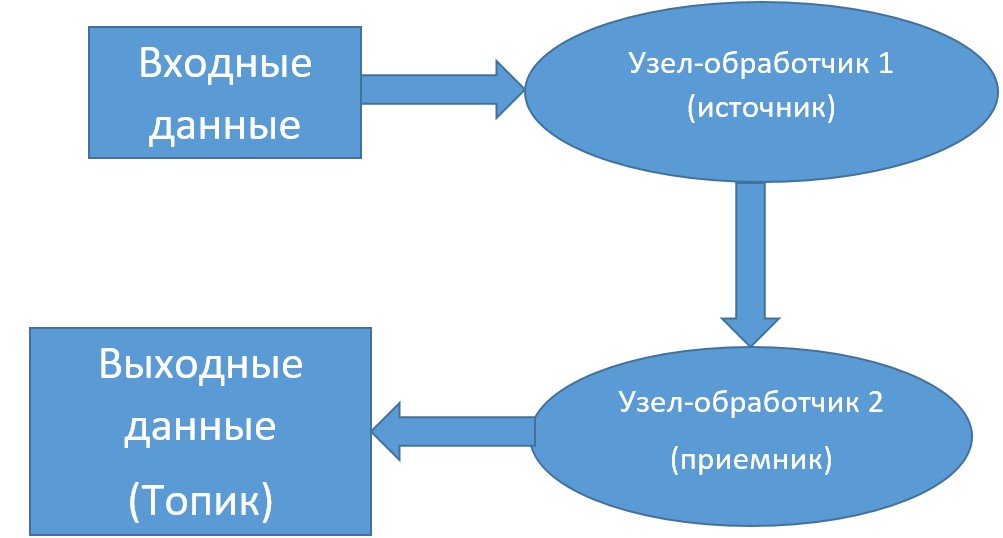
Узлы обработки реализуют различные операции над данными (фильтрация, агрегирование и т.д.). Такие узлы делятся на 2 вида:
- источники — узлы, которые потребляют входные данные и передают их дальше;
- приемники — узлы, получающие данные из источников и генерирующие новый топик.
Начало топологии DAG в Кафка Стримс всегда начинается с одного или нескольких узлов-источников и заканчивается одним или несколькими узлами-приемниками. В языке JAVA топологию потока можно задать с помощью класса KStreamBuilder:
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream(inputTopic);
Pattern pattern = Pattern.compile("\\W+", Pattern.UNICODE__CHARACTER__CLASS);
Метод stream() принимает в качестве параметра название темы и запускает поток.
Масштабирование в Kafka Streams
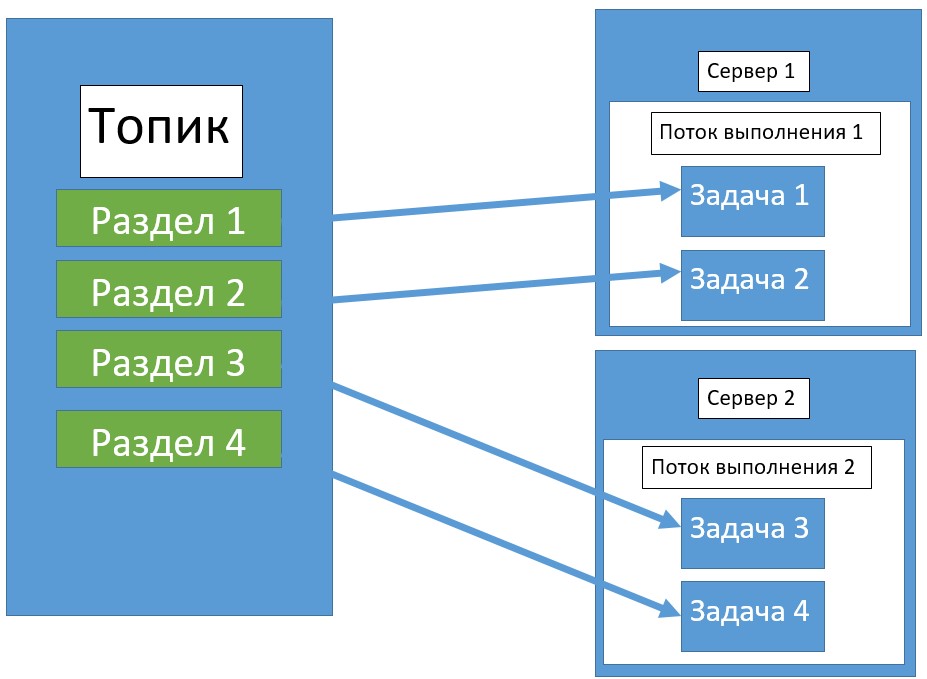
Масштабирование в Кафка Стримс — это процесс разбиения (распараллеливания) глобальной задачи на несколько параллельных подзадач с целью ускорения обработки данных. В Kafka Streams за распараллеливание отвечает специальный движок Streams, который определяет число задач с данными. Это число зависит от количества разделов (partitions) в обрабатываемых топиках (topics).
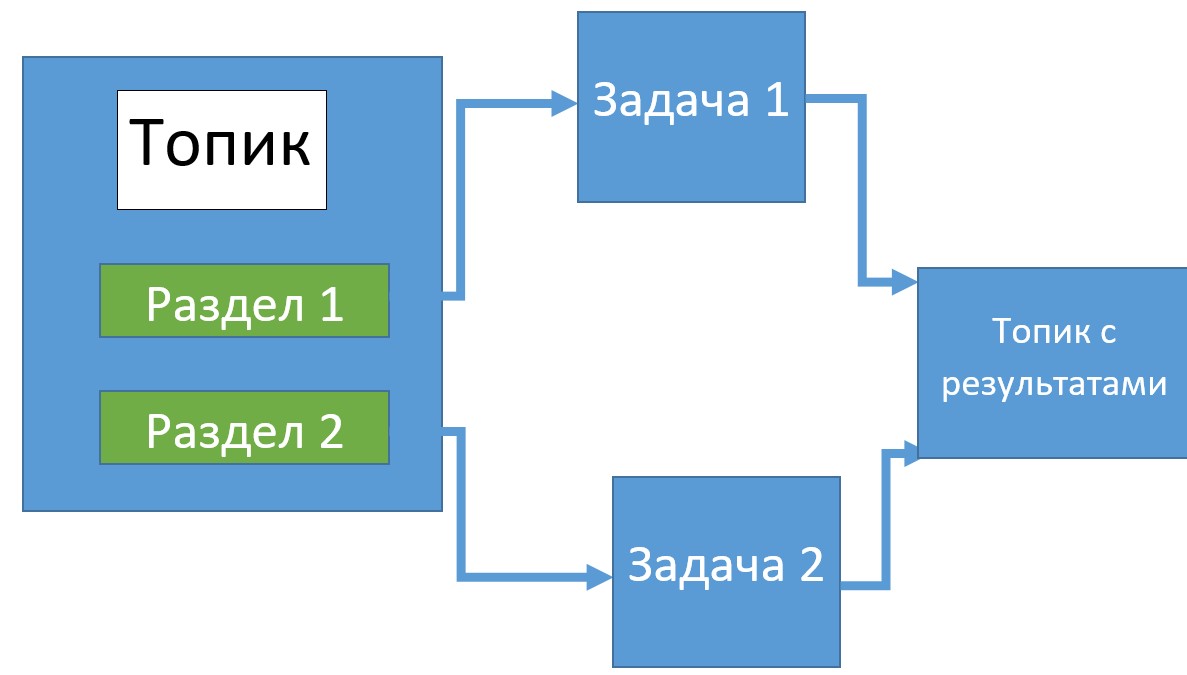
Каждая задача отвечает за определенное подмножество разделов: она подписывается на эти разделы и считывает события, происходящие в них. Для каждого считанного события задачей выполняются все необходимые шаги обработки данных. После этого формируется результат и записывается в приемник. Задачи являются базовой единицей параллелизма в Kakfa Streams, поскольку любая задача может быть выполнена независимо от остальных. У разработчика также имеется возможность создания потоков выполнения, в которые можно объединить несколько задач. Таким образом, повысить скорость обработки данных можно просто увеличив количество потоков выполнения. А если на сервере будет недостаточно ресурсов, можно запустить еще один поток выполнения на другом сервере [2].
За распараллеливание задач отвечает JAVA-класс KafkaStreams, который запускает потоки c с помощью метода start(). Далее рассмотрен пример кода, который распараллеливает потоки в созданной топологии и запускает их работу :
Map<String, Object> props = new HashMap<>(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream-processing-application"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); KafkaStreams streams = new KafkaStreams(builder, props); streams.start(); Thread.sleep(30000); streams.close();
При выполнении задач потоки необходимо закрывать при помощи метода close(), так как они резервируют ресурсы и могут препятствовать выполнению других потоков в приложении.
Таким образом, Кафка Стримс гарантирует высокую скорость обработки данных благодаря их распараллеливанию, что делает Apache Kafka полезным средством для каждого специалиста в области анализа и обработки больших данных, от Data Scientist’а до разработчика распределенных приложений. В следующей статье мы поговорим про зеркальное копирование данных в Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- https://docs.confluent.io/current/streams/index.html
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

