В прошлый раз мы говорили про зеркальное копирование в кластерах Кафка. Сегодня поговорим про соединение потоков в Kafka Streams через Join-операции. Читайте далее про процесс соединения потоков, который обеспечивает Кафке высокую отказоустойчивость к потерям исторических данных независимо от их структуры.
Оконное соединение в Kafka
Оконное соединение — это объединение двух и более потоков событий, происходящих в один и тот же промежуток времени с целью сохранения полной истории всех происходящих событий. При оконном соединении идет поиск соответствий событий из одного потока событиям из другого, которые относятся к тем же временным окнам (промежуткам времени) и с такими же ключами. В Кафке оконное соединение осуществляется с помощью библиотеки Кафка Стримс. Особенности оконного соединения мы подробно рассмотрим далее.
Соединение потоков в Kafka Streams
Kafka Streams — это клиентская библиотека, позволяющая брокеру Кафка работать в многопоточной среде. Кафка Стримс также отвечает за соединения потоков по ключам соединения. Ключи соединения потоков — это ключи потоков события, присваиваемые им в момент времени происхождения. Если события происходят в один и тот же момент времени, они получают один и тот же ключ соединения. При соединении потоки секционируются по одним и тем же ключам соединения. Затем создаются топики для каждого потока данных. Данные каждого из соединяемых потоков распределяются по разным топикам. После этого оба топика назначаются одной задаче. Таким образом, этой задаче становятся доступны оба потока [1].
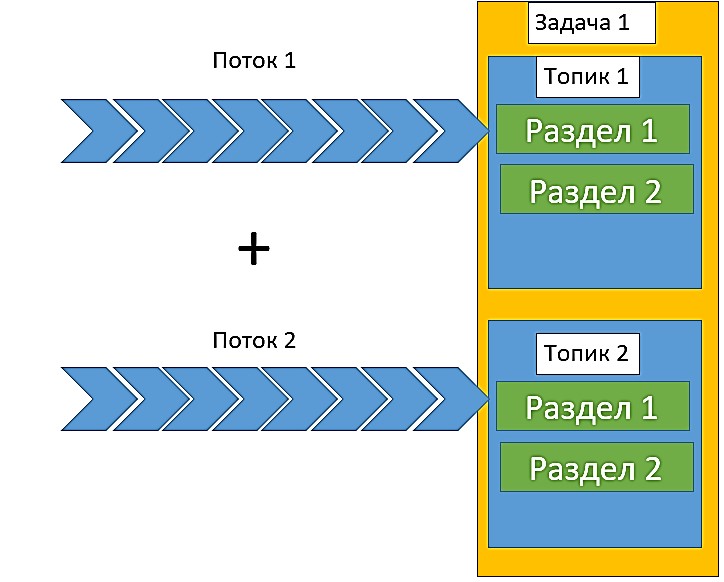
Задача хранит во встроенном кэше RocksDB временное окно соединения для обоих топиков. Благодаря этому задача может выполнить соединение потоков, находящихся в этих топиках. Далее рассмотрим пример Java-кода, который соединяет два потока, состоящих из таблиц с данными о клиентах и адресах [2]:
KStream<String,JsonNode> customers = builder.stream(" customer ", Consumed.with(stringSerde, jsonNodeSerde));
KStream<String,JsonNode> addresses = builder.stream(" address ", Consumed.with(stringSerde, jsonNodeSerde));
//Получаем id клиента в качестве ключа для дальнейшего соединения
KStream<String,JsonNode> customerRekeyed = customers.selectKey(value-> value.get(" id ").asText());
ObjectMapper mapper = new ObjectMapper();
// Получаем id клиента для агрегации адресов
KTable<String,JsonNode> addressTable = addresses
.selectKey(value-> value.get("customer_id").asText())
.groupByKey()
.aggregate(() ->mapper::createObjectNode,
(key,value,aggregate) -> aggregate.add(value),
Materialized.with(stringSerde, jsonNodeSerde));
//Соединяем потоки клиентов и адресов
KStream<String,JsonNode> customerAddressStream = customerRekeyed.leftJoin(addressTable,
(left,right) -> {
ObjectNode finalNode = mapper.createObjectNode();
ArrayList addressList = new ArrayList< JsonNode >();
((ArrayNode)right).elements().forEachRemaining(addressList :: add);
left.putArray(" addresses ").allAll(addressList);
return left;}
Joined.keySerde(stringSerde).withValueSerde(jsonNodeSerde));
Таким образом, благодаря объединению потоков Кафка исключает потерю исторических данных о происходящих событиях, а также проверяет соответствие транзакций набору хранимых в базе данных правил для корректного их выполнения. Благодаря этому Кафка является весьма надежным и отказоустойчивым брокером для хранения и обмена больших потоков данных, что позволяет активно использовать этот фреймворк в задачах Data Science и разработке распределенных приложений. В следующей статье мы поговорим про Кафка Коннект.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных
- https://docs.confluent.io/current/streams/developer-guide/dsl-api.html#joining

