
В прошлый раз мы говорили про основы работы с KSQL. Сегодня поговорим про топологию потоковой передачи в брокере Apache Kafka. Читайте далее про особенности топологии потоковой передачи, благодаря которой брокер Kafka способен обрабатывать несколько входящих потоков Big Data одновременно.
Как работает топология потоковой передачи в Apache Kafka: особенности обработки потоков Big Data
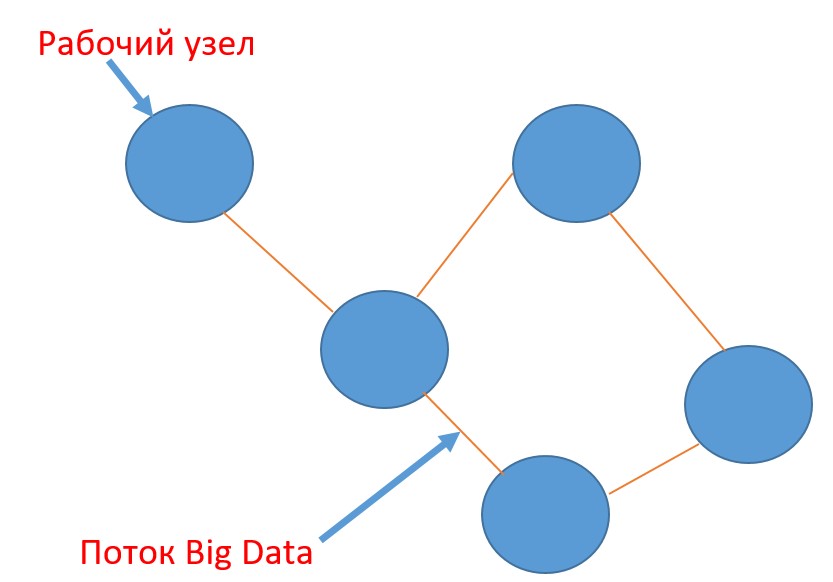
Топология потоковой передачи (ТПП) представляет собой направленный ациклический граф (Directed acyclic graph, DAG), который не содержит циклов, то есть состоит только из вершин и ребер. Причем каждое ребро направлено от одной вершины к другой так, что следование этим направлениям никогда не образует замкнутого цикла. В качестве вершин этого графа в ТПП выступают рабочие узлы, которые соединены между собой потоками, представляющими собой ребра графа.
Работа с топологией потоковой передачи в Kafka: несколько практических примеров
Для того, чтобы начать работу с ТПП в Kafka, необходимо настроить базовую конфигурацию, подгрузив необходимые библиотеки. В качестве сборщика проекта можно использовать Apache Maven, так как он имеет возможность самостоятельно подгружать необходимые библиотеки из нужных репозиториев (источников), что освобождает разработчика от необходимости «ручных» установок и тем самым значительно экономит его время. В первую очередь необходимо установить maven-зависимости для Kafka (чтобы подгрузить актуальную версию Kafka-клиента). Следующий код на языке разметки XML отвечает за настройку Kafka-зависимостей в Maven-файле pom.xml (файл зависимостей, который создается автоматически при сборке проекта с помощью Maven) [1]:
<dependency> <groupId> org.apache.kafka </groupId> <artifactId> kafka-streams </artifactId> <version> 2.6.0 </version> </dependency> <dependency> <groupId> org.apache.kafka </groupId> <artifactId> kafka-clients </artifactId> <version> 2.6.0 </version> </dependency>
Далее необходимо настроить конфигурацию для использования клиента Kafka. Следующий код на языке Java отвечает за создание класса для базовой конфигурации Kafka-клиента [2]:
public class KafkaClient{
Properties props = new Properties();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, LOCATION_OF_KAFKA_BROKERS);
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "MyStreamingApp");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, JsonObject> inputStream = builder.stream(inputTopic);
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
}
Для создания топологии потоковой передачи необходимо создать ветви (ребра), задав необходимые условия с помощью класса Predicate. Следующий код на языке Java отвечает за создание потоковой топологии с несколькими ветвями [3]:
public class KafkaTopology{
public static final double SOME_CONSTANT = 100;
// задание необходимых условий для каждой из ветвей топологии
Predicate<String, JsonObject> greaterThan = (String key, JsonObject value) -> {
double dValue = value.get("my_double_value").getAsDouble();
return dValue > SOME_CONSTANT;
};
Predicate<String, JsonObject> lessThan = (String key, JsonObject value) -> {
double dValue = value.get("my_double_value").getAsDouble();
return dValue < SOME_CONSTANT;
};
Predicate<String, JsonObject> equalTo = (String key, JsonObject value) -> {
double dValue = value.get("my_double_value").getAsDouble();
return Math.abs(dValue - SOME_CONSTANT) < epsilon;
};
Predicate<String, JsonObject>[] conditions = new Predicate<>[] { greaterThan, lessThan, equalTo };
KStream<String, JsonElement>[] branches = inputStream.branch(conditions);
branches[0].to("greater-than-topic");
branches[1].to("less-than-topic");
branches[2].to("equal-to-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
}
Как видно из кода, созданная топология разбивает входящий топик на 3 топика в зависимости от значений поля «my_double_value» в каждом из сообщений следующим образом:
- топик со значением поля больше заданного значения;
- топик со значением поля меньше заданного значения;
- топик со значением поля равным заданному значению.
Разбиение топика происходит с помощью утилиты Kafka Streams, которая создает три параллельно выполняющихся потока для одновременного создания трех топиков на Kafka-сервере.
Таким образом, благодаря топологии потоковой передачи, брокер Kafka может эффективно и достаточно быстро обрабатывать большие массивы данных, разбивая их на несколько параллельных потоков выполнения. Это делает Apache Kafka универсальным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот фреймворк в задачах Data Science и разработке распределенных приложений. В следующей статье мы поговорим про обогащение потока событий в Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- https://itnext.io/creating-a-streaming-data-pipeline-with-kafka-streams-898fb352a7b7
- https://gist.github.com/jsnouffer/29fd0748ec1629d3f94074cba4a406e7#file-kstreams-simple-java
- https://gist.github.com/jsnouffer/7a8496dfb7dd7663742a6be554955e50#file-kstreams-simple-branches-java

