В прошлый раз мы говорили про утилиту Kafka Connect. Сегодня подробнее рассмотрим механизм, позволяющий создавать сериализаторы и десериализаторы в Kafka. Читайте далее, чтобы узнать про основные особенности данного механизма для эффективной обработки Big Data в распределенной среде.
Для чего нужны сериализаторы и десериализаторы в Kafka
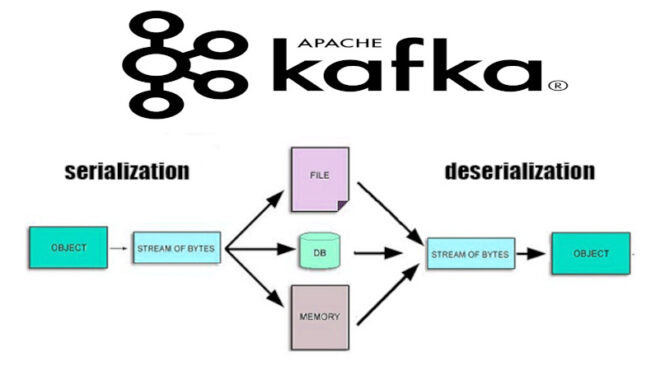
Пользовательские сериализаторы (user serializer) — это набор функций, который создается пользователем для выполнения сериализации (преобразование объекта в байтовый массив) необходимых ему объектов. Прежде, чем создавать пользовательские сериализаторы, необходимо создать класс, который реализует (implements) интерфейс Serializer, требующий определение (или переопределение) методов configure() (для предварительной настройки, например проверка на наличие ключей или настройки отдельных ссылок), serialize() (для сериализации соответственно), который в качестве параметров принимает топик и данные для сериализации в этом топике, а также возвращает результат типа byte-массива и close() для закрытия потоков.
Десериализация (deserialization) — это процесс создания структуры данных из битовой последовательности путем перевода этой последовательности в объекты и их упорядочивания (структуризации). Для десериализации данных используются десериализаторы. Десериализатор (deserializer) — это объект (или класс), который представляет собой набор функций и методов для десериализации данных. Брокер Kafka использует десериализаторы для преобразования записей в объекты Java.
Особенности работы сериализаторов и десериализаторов в Kafka: несколько практических примеров
По умолчанию для десериализаций событий (например, подключение к серверу Kafka или регистрация нового потребителя) Kafka использует Java-десериализаторы StringDeserializer. Следующий код на языке Java отвечает за настройку брокеров Kafka:
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
// используемый десериализатор
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Однако стоит отметить, что StringSerializer можно использовать только в том случае, если наверняка известно, что все события представляют из себя набор строковых объектов. В противном случае существует риск получить ошибку типа SerializationException. Для того, чтобы этого избежать, можно пользоваться пользовательским десериализатором. В качестве примера можно рассмотреть пользовательский объект Customer, который представлен набором полей:
public class Customer {
private int customerID;
private String customerName;
public Customer(int ID, String name) {
this.customerID = ID;
this.customerName = name;
}
public int getID() {
return customerID;
}
public String getName() {
return customerName;
}
}
Для данного объекта можно написать пользовательский десериализатор, который представляет собой Java-класс, использующий интерфейс Deserializer. В этом классе необходимо переопределить метод deserialize()[1]:
import org.apache.kafka.common.errors.SerializationException;
import java.nio.ByteBuffer;
import java.util.Map;
public class CustomerDeserializer implements
Deserializer<Customer> {
@Override
public Customer deserialize(String topic, byte[] data) {
int id;
int nameSize;
String name;
try {
if (data == null)
return null;
// количество данных должно быть неменее 8 бит
if (data.length < 8)
throw new SerializationException("Size of data received by
IntegerDeserializer is shorter than expected");
// десериализация данных
ByteBuffer buffer = ByteBuffer.wrap(data);
id = buffer.getInt();
String nameSize = buffer.getInt();
byte[] nameBytes = new Array[Byte](nameSize);
buffer.get(nameBytes);
name = new String(nameBytes, 'UTF-8');
return new Customer(id, name);
} catch (Exception e) {
throw new SerializationException("Error when serializing
Customer
to byte[] " + e);} }
В качестве сериализатора рассмотрим пример пользовательского сериализатора для созданного класса Customer, код для которого выглядит следующим образом [1]:
public class Customer {
private int customerID;
private String customerName;
public Customer(int ID, String name) {
this.customerID = ID;
this.customerName = name;
}
public int getID() {
return customerID;
}
public String getName() {
return customerName;
}
}
Как видно из кода, класс Customer имеет строковое поле name, которое будет сериализоваться у каждого созданного экземпляра этого класса. Для того, чтобы создать класс-сериализатор, необходимо реализовать generic-интерфейс (этот интерфейс не имеет собственного типа, он принимает тип указанного в нем объекта). Следующий код на языке Java отвечает за создание класса-сериализатора для класса Customer [1]:
public class CustomerSerializer implements Serializer<Customer> {
@Override
public void configure(Map configs, boolean isKey) {
// в данном примере нет параметров для отдельной конфигурации
}
@Override
public byte[] serialize(String topic, Customer data) {
try {
byte[] serializedName;
int stringSize;
if (data == null)
return null;
else {
if (data.getName() != null) {
serializedName = data.getName().getBytes("UTF-8");
stringSize = serializedName.length;
} else {
serializedName = new byte[0];
stringSize = 0;
}}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + stringSize);
buffer.putInt(data.getID());
buffer.putInt(stringSize);
buffer.put(serializedName);
return buffer.array();
} catch (Exception e) {
throw new SerializationException("Error when serializing Customer to
byte[] " + e);
}}
@Override
public void close() {
// нечего закрывать, так как нет потоков
}}
Таким образом, благодаря поддержке механизмов сериализации и десериализации, брокер Kafka гарантирует качественную обработку Big Data из любого источника (электронная почта, социальные сети, системы уведомлений). Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных