В прошлый раз мы говорили про потоки событий в брокере Kafka. Сегодня поговорим про фиксации смещений в Kafka. Читайте далее про особенности фиксаций смещений, благодаря которым брокер Kafka может легко добавлять новые записи Big Data в топики, а также получать доступ к старым.
Как работают фиксации смещений в брокере Apache Kafka: особенности обработки записей Big Data
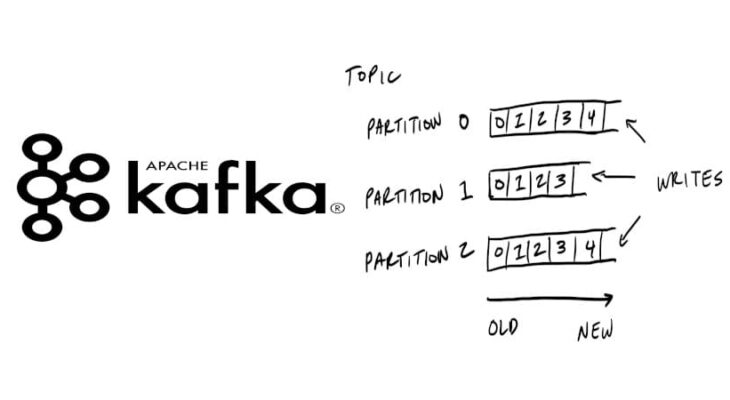
Смещение (offset) в Kafka — это индекс (порядковый номер), указывающий на положение записи в разделе (partititon) топика. Информация о смещениях (порядковые номера всех сообщений) хранится в специальном топике __consumer_offsets. Kafka узнает о появлении новой записи (сообщений) благодаря механизму фиксации смещений. Фиксация смещений — это обновление текущей позиции (или добавление новой) записи в разделе топика [1]. Существуют следующие виды фиксаций смещений:
- синхронная фиксация смещений;
- асинхронная фиксация смещений.
Каждый из этих видов мы подробнее рассмотрим далее.
Синхронная фиксация смещений
Синхронная фиксация смещений — это автоматическая фиксация текущего смещения записи в момент ее появления. Как только смещение успешно фиксируется, выполнение процедуры завершается. В случае сбоя синхронной фиксации генерируется исключение, и фиксация возобновляется, выполняясь до тех пор, пока смещение не зафиксируется. Следующий код на языке Java отвечает за выполнение синхронной фиксации смещений записей с помощью метода commitSync() [2]:
while (true) {
ConsumerRecords< String, String > records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records){
System.out.printf("topic = %s, partition = %s, offset =
%d, customer = %s, country = %s\n",
record.topic(), record.partition(),
record.offset(), record.key(), record.value());
}
try {
consumer.commitSync();
} catch (CommitFailedException e) {
log.error("commit failed", e)}}
Из кода видно, что фиксация смещения происходит после получения приложением каждой записи (с помощью метода poll()). Метод commitSync() будет повторять фиксацию каждой новой записи до тех пор, пока не возникнет непоправимая ошибка типа CommitFailedException (например, полный выход из строя Kafka-сервера). Если произойдет такая ошибка, сведения о ней автоматически запишутся в журнал логирования (logging), который содержит информацию об этапах выполнения программы.
Асинхронная фиксация смещений
При синхронной фиксации смещений приложение блокируется (остальные функции и запросы становятся недоступны) до тех пор, пока брокер Kafka не подтвердит успешную фиксацию. Это ограничивает пропускную способность (количество информации, передаваемое в единицу времени) приложения. В этом случае можно использовать асинхронную фиксацию. Асинхронная фиксация смещений — это фиксация, которая выполняется независимо (параллельно) от выполнения остальных функций приложения и не требует обязательного подтверждения факта успешной фиксации от Kafka-сервера. Следующий код на языке Java отвечает за выполнение асинхронной фиксации смещения записей в топике с помощью метода commitAsync() [2]:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records){
System.out.printf("topic = %s, partition = %s,
offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());}
consumer.commitAsync();
}
Главное отличие между асинхронной и синхронной фиксациями состоит в том, что синхронная фиксация будет повторять попытку фиксации смещения до тех пор, пока она не завершится успешно (за исключением полного выхода из строя сервера Kafka). Асинхронная фиксация, в случае возникновения ошибочной ситуации (например, истечение времени ожидания или временный сбой Kafka-сервера), не станет повторять попытку фиксации смещения текущей записи, а сразу перейдет к фиксации смещения следующей доступной (или поступившей) записи [2].
Таким образом, благодаря механизму управления фиксациями, брокер Kafka может весьма эффективно регистрировать новые записи Big Data в топиках, обращаться к старым, а также удалять из топиков записи, которые более не используются. Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений. В следующей статье мы поговорим про перебалансировку разделов в Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- https://habr.com/ru/company/piter/blog/352978/
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

