В прошлой статье мы говорили про основные принципы работы кластера Apache Kafka. Сегодня рассмотрим, из каких элементов состоит система обмена данными в этом брокере сообщений. Читайте далее про обмен данными в Apache Kafka, благодаря которому эта стриминговая платформа является таким мощным средством хранения и обмена больших данных.
Компоненты системы обмена данными в Kafka
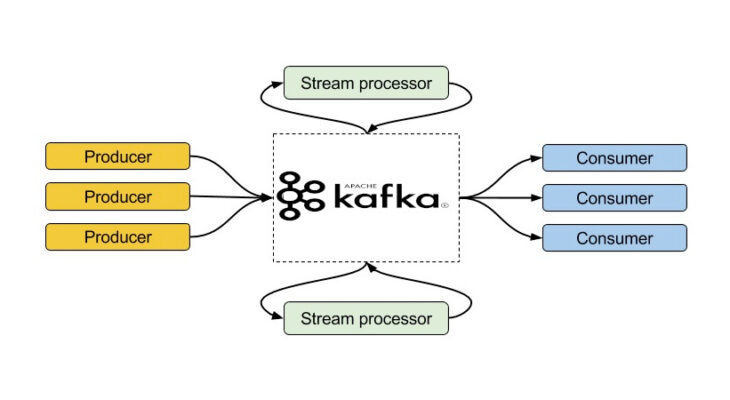
В мире Big Data именно Apache Kafka считается самым лучшим брокером сообщений. Таковым ее делает универсальная система обмена данными, которая включает в себя следующие компоненты:
- топик;
- потребитель (consumer);
- издатель (producer).
Каждый из этих компонентов мы подробнее рассмотрим далее.
Топик
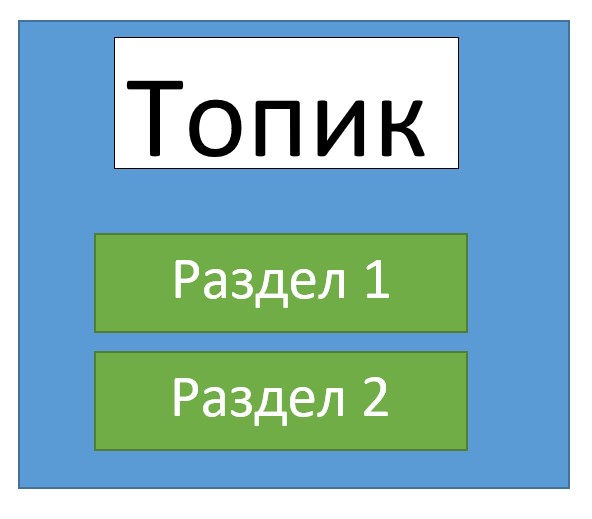
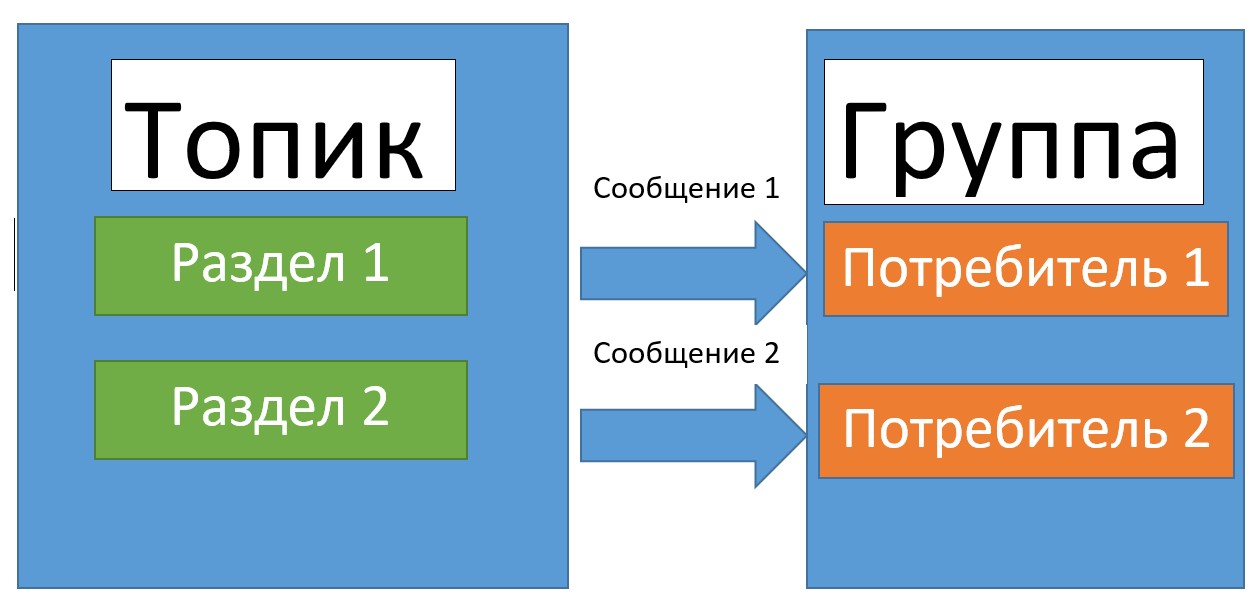
Топик (topic) – это элемент Kafka, который объединяет все сообщения, относящиеся к одной тематике. Прежде, чем начать обмен сообщениями, необходимо создать топик, в котором эти сообщения будут храниться для последующей их рассылки. Все сообщения, которые хранятся в топике, образуют очередь. Для того, чтобы читать актуальные сообщения из этой очереди, в каждом топике есть специальный указатель (offset), который отвечает за cмещение курсора на следующее сообщение в очереди. Это называется фиксацией чтения (commit).

Однако бывают такие случаи, когда сообщение в топики приходят быстрее, чем уходят из него. Специально для этого в Kafka-топиках предусмотрены разделы (partition), которые разделяют очереди с целью защиты топика от переполнения [1].
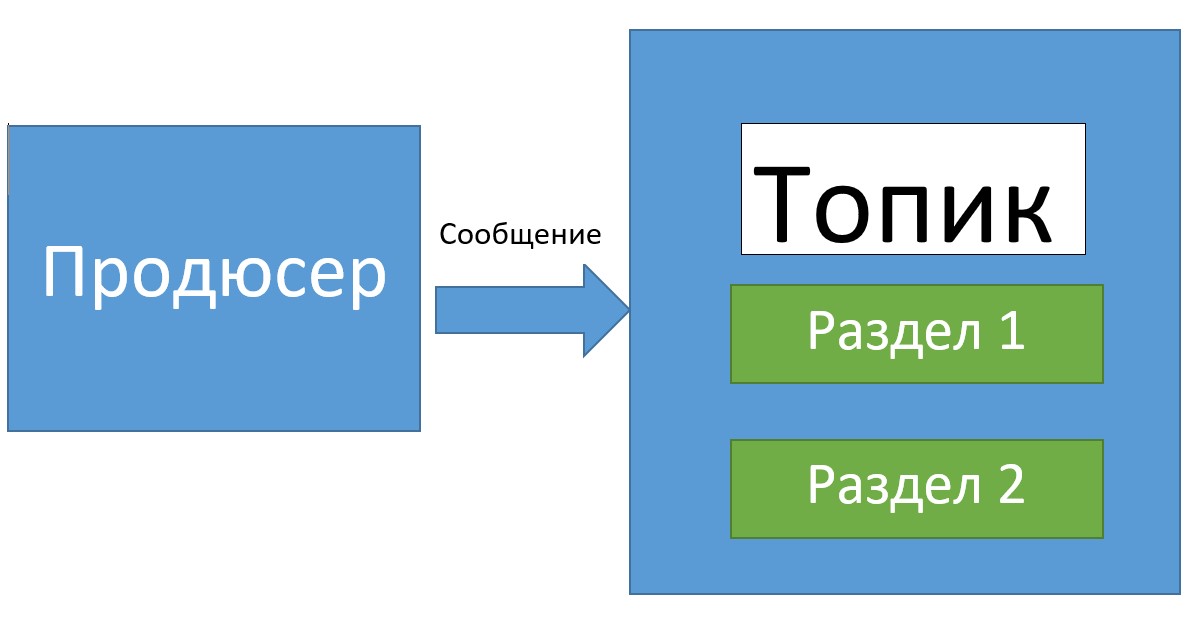
Издатель
Издатель (producer) — это сервис, отвечающий за создание и отправку сообщений в топики. Для отправки сообщения продюсеру необходимо знать название топика и порт, по которому доступен узел с этим топиком. Все сообщения, отправленные продюсером, распределяются по разделам топика и ждут своего «прочтения».
Рассмотрим пример создания класса «Producer» на JAVA:
public class Producer {
public static void main(String[] args) throws Exception {
if (args.length == 0) {
System.out.println("Enter topic name");
return;
}
String topic = args[0].toString();
System.out.println("Producer topic=" + topic);
Properties props = new Properties();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer(props);
BufferedReader br = null;
reader = new BufferedReader(new InputStreamReader(System.in));
System.out.println("Enter key:value, q - Exit");
while (true) {
String input = reader.readLine();
String[] split = input.split(":");
if ("q".equals(input)) {
producer.close();
System.out.println("Exit!");
System.exit(0);
} else {
switch (split.length) {
case 1:
producer.send(new ProducerRecord(topicName, split[0]));
break;
case 2:
producer.send(new ProducerRecord(topicName, split[0], split[1]));
break;
case 3:
producer.send(new ProducerRecord(topicName, Integer.valueOf(split[2]), split[0], split[1]));
break;
default:
System.out.println("Enter key:value, q - Exit"); }}}}}
Класс Properties представляет собой коллекцию сущностей, которые содержат информацию о подключении к серверу (номер порта, количество выделяемой памяти и т.д.). За отправку сообщения в топик отвечает метод send(). Для реализации среды отправки сообщений в реальном времени используется бесконечный цикл while(true).
Потребитель
Потребитель (consumer) — это сервис, отвечающий за получение данных из Kafka-топика. Для получения сообщений, потребителю, также, как и продюсеру, необходимо иметь информацию о сервере (порт, URL) и имени топика, из которого необходимо получать данные. В случае разделения очередей в топике по разделам потребители объединяются в группы. Каждая группа потребителей получает данные из определенного раздела.
Класс «Consumer» также, как и «Producer» использует коллекцию сущностей (properties) для получения доступа к данным топика. Пример кода на Java будет выглядеть следующим образом:
public class Consumer {
public static void main(String[] args) throws Exception {
if (args.length != 3) {
System.out.println("Enter topic name, groupId, clientId");
return;
}
final String topic = args[0].toString();
final String groupId = args[1].toString();
final String clientId = args[2].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", groupId);
props.put("client.id", clientId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topicName));
System.out.println("Subscribed to topic=" + topic + ", group=" + groupId + ", clientId=" + clientId);
SimpleDateFormat format = new SimpleDateFormat("HH:mm:ss");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s, time = %s \n",record.offset(),record.key(),record.value(),format.format(new Date()));}}}

Для получения данных используется метод poll(), который в качестве параметра принимает тайм-аут ожидания сообщения. По истечении этого времени он «засыпает». Это реализовано для того, чтобы в многопоточной среде избежать блокировки выполнения других потоков. При появлении нового сообщения метод возвращает его и опять ожидает в течение заданного тайм-аута [2].
Исходя из всего вышесказанного, система обмена сообщениями в Apache Kafka гарантирует высокую отказоустойчивость и доставляет данные любого объема по заданному адресату благодаря распределению очередей по разделам и объединения получателей в группы для работы с ними. Все это делает Apache Kafka полезным средством для каждого специалиста в области анализа и обработки больших данных, от Data Scientist’а до разработчика распределенных приложений. В следующей статье мы поговорим про технологию работы с потоками Kafka Streams.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники

