
В прошлой статье мы говорили об архитектуре кластера Apache Kafka. Сегодня рассмотрим, какие элементы входят во внутренний механизм Kafka, делая ее лучшим брокером сообщений в мире Big Data. Читайте далее про внутреннее устройство Apache Kafka и принципы репликации больших данных.
Главные компоненты внутренней структуры кластера Kafka для работы в мире Big Data
Напомним, Apache Kafka представляет собой целую распределенную систему обмена данными. Таким образом, обработка и хранение данных происходит в кластере, который содержит в себе, как правило, несколько брокеров (узлов), которые тесно связаны между собой. В этой статье мы разберем основные элементы внутренней структуры кластера для нормальной работы всех брокеров, входящих в него. Итак, работу кластера обеспечивают следующие составляющие:
- контролер;
- механизм репликации;
Работу каждого из этих компонентов мы подробнее рассмотрим далее.
Механизм репликации
Репликация – это процесс копирования данных из одного узла на другой. Механизм репликации обеспечивает сохранность данных при сбое или выходе из строя отдельных брокеров в кластере. В Apache Kafka все данные сгруппированы по темам, которые разбиваются на разделы, у каждого из которых могут быть несколько копий (реплик). Эти реплики хранятся на брокерах, каждый из которых может хранить несколько тысяч таких реплик. Существует два вида реплик:
- ведущие – реплики, через которые выполняются клиентские запросы;
- ведомые – реплики, которые копируют сообщения из ведущей реплики, тем самым поддерживая актуальное состояние по сравнению с ней.
Ведомые реплики поддерживают актуальное состояние посредством репликации (копирования) всех данных от ведущих реплик по мере их поступления. Бывают случаи, когда ведомые реплики начинают отставать от ведущих. Виной этому могут стать множество причин, например, перегруженность сети или аварийная остановка брокера. Чтобы восстановить свое актуальное состояние, ведомые реплики посылают ведущим запросы (fetch) со смещением (offset). В ответ на них ведомые реплики присылают сообщения в порядке, указанном в смещении [1].

Контроллер
Контроллер – это брокер, который отвечает за выбор ведущих реплик для разделов. Контроллером становится брокер, который был запущен раньше остальных.
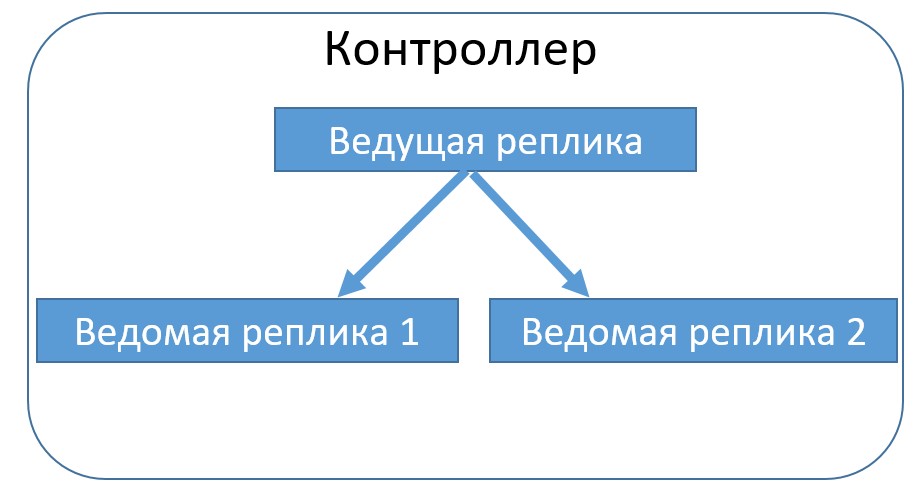
Он создает в службе ZooKeeper временный узел с названием /controller. Другие брокеры при запуске тоже попытаются стать «контроллерами», но получат исключение, что «такой узел уже существует». Каждый брокер в кластере создает таймер на узле-контроллере для оповещения об изменениях, которые происходят на нем. Таким образом, кластер будет иметь только один контроллер в заданный момент времени. В случае остановки брокера-контроллера или разрыва его соединения со службой ZooKeeper временный узел исчезает, и другие брокеры будут знать об этом благодаря таймеру оповещений. В таком случае каждый из этих брокеров снова попытается создать временный узел и стать контроллером. Новым контроллером станет брокер, который первым создаст временный узел. Таким образом, кластер никогда не останется без активного контроллера [2].
Таким образом, механизмы контроллеров и репликации кластера Kafka обеспечивает высокую отказоустойчивость и целостность всей Big Data системы, делая ее полезным средством для каждого специалиста в области анализа и обработки больших данных, от Data Scientist’а до разработчика распределенных приложений. В следующей статье мы поговорим о системе обмена сообщениями в Apache Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- https://coderlessons.com/tutorials/bolshie-dannye-i-analitika/vyuchit-apache-kafka/apache-kafka-kratkoe-rukovodstvo
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

