
В этой статье поговорим про Apache Kafka – распределенный программный брокер сообщений для организации очередей в целях отслеживания больших потоков входных данных. Читайте далее, какие ключевые особенности Кафки делают ее настолько полезным и привлекательным средством для практического применения в Data Science.
Чем хороша Кафка: 3 главных преимущества
Одним из наиболее значимых преимуществ Apache Kafka является ее пропускная способность – при увеличении количества источников идет наращивание пропускной способности за счет горизонтальной масштабируемости. За счет этого многие задачи по хранению и обработке больших массивов входных и выходных данных выполняются быстрее, что особенно важно при оперативном оповещении всех клиентов о наступающем событии. Стоит также отметить многофункциональность Кафки, которая достигается за счет технологии Kafka Streams. Kafka Streams – это клиентская библиотека, которая позволяет разработчику взаимодействовать с данными, которые хранятся в топиках Кафка, KSQL для анализа Big Data и Kafka Connect для интеграции данных. Однако это далеко не все плюсы Кафки. С практической точки зрения весьма полезны следующие ее свойства, каждое из которых мы подробнее рассмотрим далее:
- надежность системы;
- высокая производительность;
- статус динамично развивающегося open-source проекта с активным профессиональным сообществом.
Надежность системы
Apache Kafka позволяет вести надежный обмен сообщениями без различных потерь за счет своей распределенной структуры. Это достигается благодаря тому, что все сообщения хранятся на дисках, которые предполагают репликацию внутри кластера (резервное копирование из одного источника на другой). Таким образом, если произойдет непредвиденный сбой системы, всю информацию можно будет восстановить немедленно и без потерь.
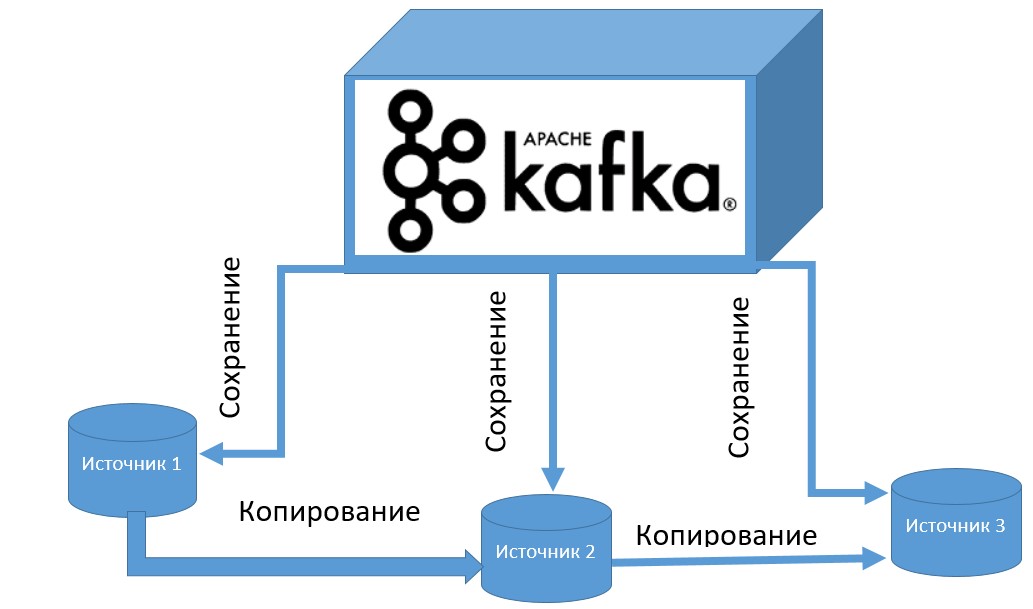
Kafka также может сохранять и отслеживать текущее состояние системы за счет смещения (offset) топиков, что обеспечивает достоверность исторической информации о больших данных.
Высокая производительность
Поскольку Кафка является распределенной системой, она дает возможность масштабировать ее в соответствии с требованиями к данным. Благодаря технологии Kafka Streams существует возможность обработки больших объемов данных. Это достигается за счет того, что при каждом считывании данных из определенной темы создается новый поток (stream), который создает тему для записи туда уже считанных и обработанных данных. Благодаря работе с большими RAID-массивами сервера (Redundant Array of Independent Disks) запись, считывание и обработка данных происходят довольно быстро.
Кафка – это средство с открытым исходным кодом
Входя в линейку проектов Apache Software Foundation, Кафка продолжает активно развиваться за счет большого сообщества разработчиков. Энтузиасты open-source улучшают основной софт и предлагают дополнительные пакеты. Например, 3 августа 2020 года состоялся выход последней версии Кафка (2.6.0). Это избавило пользователя от ручной настройки заголовков HTTP-ответов для Kafka Connect. Теперь можно добавлять пользовательские заголовки ко всем REST-ответам (Representational State Transfer). За счет этого у пользователя появилась гарантия того, что REST-ответы будут соответствовать необходимым корпоративным политикам безопасности.
Комбинация всех вышерассмотренных преимуществ в рамках одного брокера сообщений делает Кафку полезным средством для каждого специалиста в области Big Data, от Data Scientist’а до разработчика распределенных приложений. В следующей статье мы расскажем про структуру брокера Кафка.
Освоить Кафку на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Кафке в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:

