Apache Kafka — это распределенная система обмена сообщениями, предназначенная для обработки и передачи данных в реальном времени. Репликация в Kafka — это ключевая функциональность, обеспечивающая отказоустойчивость и надежность данных. В этой статье мы рассмотрим, как настроить репликацию в Kafka.
Особенности настройки репликации в Kafka: несколько практических примеров
Прежде чем начать настраивать репликацию, разберем некоторые понятия, связанные с ней [1]:
- Брокеры (Brokers): узлы, на которых запущен Kafka. Каждый брокер хранит определенную часть данных и обрабатывает запросы от клиентов.
- Топики (Topics): категории, в которых хранятся сообщения. Производители (Producers) пишут сообщения в топики, а потребители (Consumers) читают их.
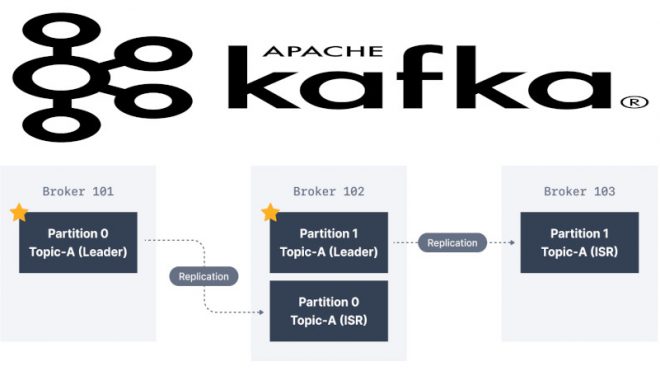
- Партиции (Partitions): топики разбиваются на партиции, что позволяет обеспечивать параллельную обработку данных. Каждая партиция реплицируется для обеспечения отказоустойчивости.
- Репликация (Replication): процесс создания дополнительных копий партиций для обеспечения отказоустойчивости. Репликация обеспечивает сохранность данных в случае сбоя брокера.
Для включения репликации на брокере необходимо добавить следующие параметры в конфигурационный файл Kafka (server.properties):
# Уникальный идентификатор брокера broker.id=1 # Путь к каталогу для хранения данных и журналов log.dirs=/path/to/data/directory # Адрес для прослушивания подключений listeners=PLAINTEXT://:9092 # Адреса брокеров в кластере advertised.listeners=PLAINTEXT://your.broker.address:9092 # Количество реплик для каждой партиции default.replication.factor=3
Следующий код на языке Java отвечает за создание топика с тремя партициями и тремя репликами в Kafka [2]:
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import java.util.Properties;
import java.util.Collections;
public class CreateTopicExample {
public static void main(String[] args) {
// Конфигурация административного клиента
Properties adminProps = new Properties();
adminProps.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "your.broker.address:9092");
try (AdminClient adminClient = AdminClient.create(adminProps)) {
// Имя топика
String topicName = "my_topic";
// Количество партиций и реплик
int numPartitions = 3;
short replicationFactor = 3;
// Создание нового топика
NewTopic newTopic = new NewTopic(topicName, numPartitions, replicationFactor);
// Создание топика с указанными параметрами
adminClient.createTopics(Collections.singletonList(newTopic));
System.out.println("Топик " + topicName + " успешно создан с " +
numPartitions + " партициями и " + replicationFactor + " репликами.");
} catch (Exception e) {
e.printStackTrace();
}
}
}
Здесь необходимо заменить your.broker.address:9092 на фактический адрес и порт используемого брокера Kafka. Данный код также использует AdminClient для создания нового топика с указанным именем, количеством партиций и фактором репликации.
Таким образом, благодаря механизму репликации, брокер Kafka гарантирует высокую безопасность и отказоустойчивость, что повышает надежность при работе с данными.
Это делает Apache Kafka надежным и универсальным средством для хранения и обмена большими потоками данных, что активно применяется в задачах Data Science и разработке распределенных приложений.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- https://habr.com/ru/companies/otus/articles/790504/
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

