Apache Kafka — это популярный и масштабируемый инструмент для обработки потоковых данных. Одной из ключевых характеристик Kafka является его способность репликации данных, что обеспечивает надежность и отказоустойчивость. Репликация в Kafka позволяет создавать кластеры брокеров и сохранять копии данных на нескольких машинах. В этой статье мы рассмотрим, как настроить и использовать репликацию в Kafka.
Репликация в Kafka: особенности настройки с практическими примерами
Прежде, чем рассматривать репликацию в Kafka, необходимо объяснить следующие понятия [1]:
- Брокеры (Brokers): Брокеры — это серверы, на которых запущен Kafka. Они хранят данные и обслуживают запросы от производителей и потребителей.
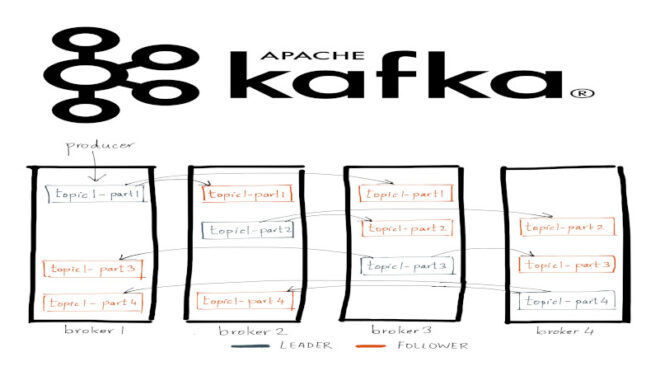
- Партиции (Partitions): Топики разделяются на партиции, что позволяет распределить данные по брокерам. Каждая партиция реплицируется на несколько брокеров.
- Реплика (Replica): Реплика — это копия партиции на другом брокере. Она служит для обеспечения отказоустойчивости и увеличения пропускной способности.
Репликация в Kafka работает на основе принципа лидера и последователя. Для каждой партиции в топике определена одна реплика как лидер (leader replica) и одна или несколько реплик-последователей (follower replicas). Лидер отвечает за запись и чтение данных, а последователи служат для резервного копирования данных. Если лидер выходит из строя, одна из реплик-последователей автоматически выбирается в качестве нового лидера. Когда данные публикуются в топик, они сначала записываются на лидере. Затем лидер передает данные своим последователям в асинхронном режиме. Это обеспечивает высокую производительность, поскольку производители и потребители работают с лидером, и данные реплицируются в фоновом режиме.
Для настройки репликации в Kafka требуется определить параметры в конфигурации брокера. Ниже приведен пример конфигурации в файле server.properties:
# Уникальный идентификатор брокера broker.id=1 # Список адресов брокеров в кластере listeners=PLAINTEXT://localhost:9092 # Директория для хранения данных и реплик log.dirs=/tmp/kafka-logs # Количество реплик для каждой партиции default.replication.factor=3
В данной конфигурации мы устанавливаем broker.id, указываем адрес и порт для прослушивания запросов, определяем директорию для хранения данных и указываем default.replication.factor, который определяет количество реплик для каждой партиции. После настройки данных свойств каждый топик будет реплицированным. Рассмотрим пример работы продюсера с реплицированным топиком [2]:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class ProducerExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
String topic = "my-replicated-topic";
// Отправляем сообщение
producer.send(new ProducerRecord<>(topic, "key", "value"));
producer.close();
}
}
Таким образом, репликация в Apache Kafka обеспечивает надежность и отказоустойчивость для распределенной обработки Big Data. Это делает Apache Kafka надежным и универсальным средством для хранения и обмена большими потоками данных, что активно применяется в задачах Data Science и разработке распределенных приложений.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800 руб.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- https://kafka.apache.org/documentation/
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

