
В прошлый раз мы говорили про работу с потоками в Apache Kafka. Сегодня рассмотрим зеркальное копирование в Kafka-кластерах и разберем базовые элементы, на которых оно основано. Читайте далее про элементы зеркального копирования, которые обеспечивают Apache Kafka высокую отказоустойчивость к потерям данных независимо от их структуры.
Структура зеркального копирования Apache Kafka
Зеркальное копирование в Apache Kafka — это обращение к записям из разделов основного кластера с целью создания локальной копии на дополнительном (целевом) кластере. В Kafka зеркальное копирование данных осуществляется с помощью утилиты Mirror Maker. Особенности использования этой утилиты мы подробнее рассмотрим далее.
Утилита Mirror Maker
Mirror Maker — это утилита Apache Kafka, которая позволяет осуществлять зеркальное копирование данных. Она представляет собой набор потребителей (consumer), которые состоят в одной группе и читают данные из выбранного для копирования набора топиков (topic). При зеркальном копировании Mirror Maker запускает для каждого потребителя поток выполнения, который считывает данные из нужных топиков и разделов исходного кластера. Затем создается производитель (producer) для отправки считанных данных на целевой кластер [1].
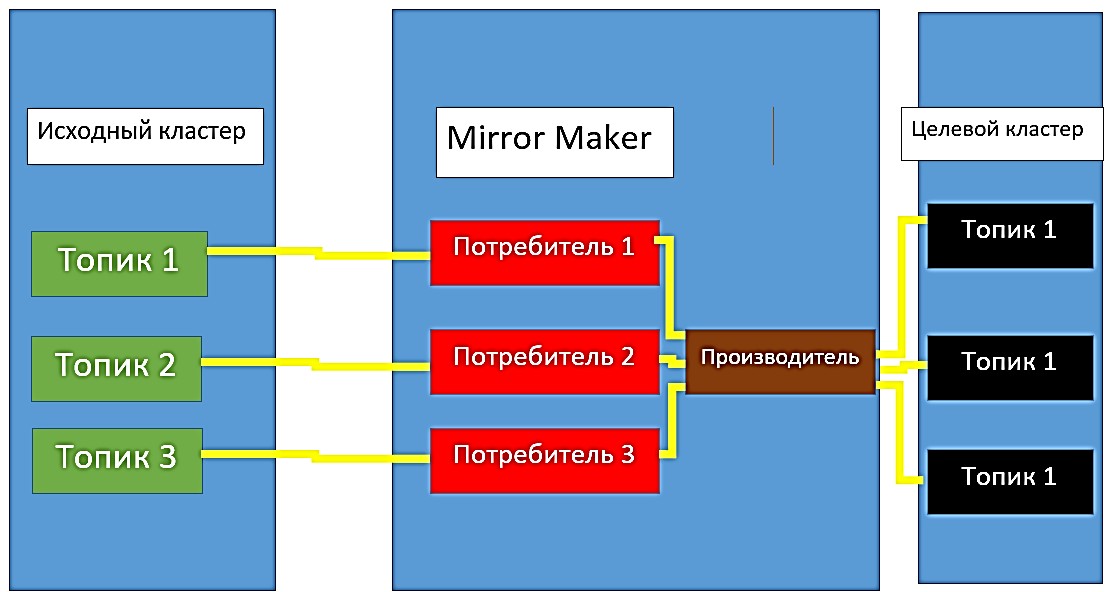
Каждые 60 секунд потребители уведомляют производителя о необходимости отправки информации об имеющихся данных. Затем потребители обращаются к исходному кластеру Kafka для фиксации смещения этих данных.
Для того, чтобы начать копирование, необходимо получить список топиков с данными, которые нужно скопировать из исходного кластера. Далее рассмотрим пример кода, который формирует список топиков с данными на исходном кластере для их копирования на целевой кластер под другими именами:
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import kafka.consumer.BaseConsumerRecord;
import kafka.tools.MirrorMaker;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.ProducerRecord;
public class RenameTopicHandler implements MirrorMaker.MirrorMakerMessageHandler {
private final HashMap<String, String> topicMap = new HashMap<String, String>();
public RenameTopicHandler(String topicList) {
String[] topicAssignments = topicList.split(";");
for (String topicAssignment : topicAssignments) {
String[] topicsArray = topicAssignment.split(",");
if (topicsArray.length == 2) {
topicMap.put(topicsArray[0], topicsArray[1]);
}
}
}
public List<ProducerRecord<byte[], byte[]>> handle(BaseConsumerRecord record) {
String targetTopic = null;
if (topicMap.containsKey(record.topic())) {
targetTopic = topicMap.get(record.topic());
} else {
targetTopic = record.topic();
}
Long timestamp = record.timestamp() == ConsumerRecord.NO_TIMESTAMP ? null : record.timestamp();
return Collections.singletonList(new ProducerRecord<byte[], byte[]>(targetTopic, null, timestamp, record.key(), record.value(), record.headers()));
}
}
Для зеркального копирования также следует сохранять полную структуру исходных данных, чтобы они были корректно «отражены». Следующий код «зеркально отражает» структуру исходных данных для копирования их на целевой кластер [2]:
import java.util.Collections;
import java.util.List;
import kafka.consumer.BaseConsumerRecord;
import kafka.tools.MirrorMaker;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.record.RecordBatch;
public class ExactMessageHandler implements MirrorMaker.MirrorMakerMessageHandler {
public List<ProducerRecord<byte[], byte[]>> handle(BaseConsumerRecord record) {
Long timestamp = record.timestamp() == RecordBatch.NO_TIMESTAMP ? null : record.timestamp();
return Collections.singletonList(new ProducerRecord<byte[], byte[]>(record.topic(), record.partition(), timestamp, record.key(), record.value(), record.headers()));
}
}
Таким образом, благодаря механизму зеркального копирования Apache Kafka является весьма надежным и отказоустойчивым брокером для хранения и обмена больших потоков данных. В следующей статье мы поговорим про соединение потоков в Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных
- https://github.com/opencore/mirrormaker_topic_rename/tree/master/src/main/java/com/opencore

