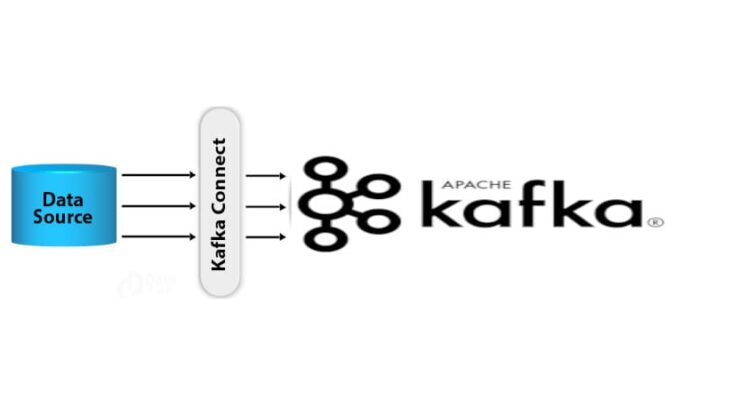
В прошлый раз мы говорили про соединение потоков в Kafka. Сегодня рассмотрим базовые принципы устройства еще одной утилиты брокера Kafka для интеграции с внешними системами Kafka Connect. Читайте далее про архитектуру интеграционной библиотеки, благодаря которой Apache Kafka легко взаимодействует с различными Big Data хранилищами и базами данных.
Плагины-коннекторы в Kafka Connect
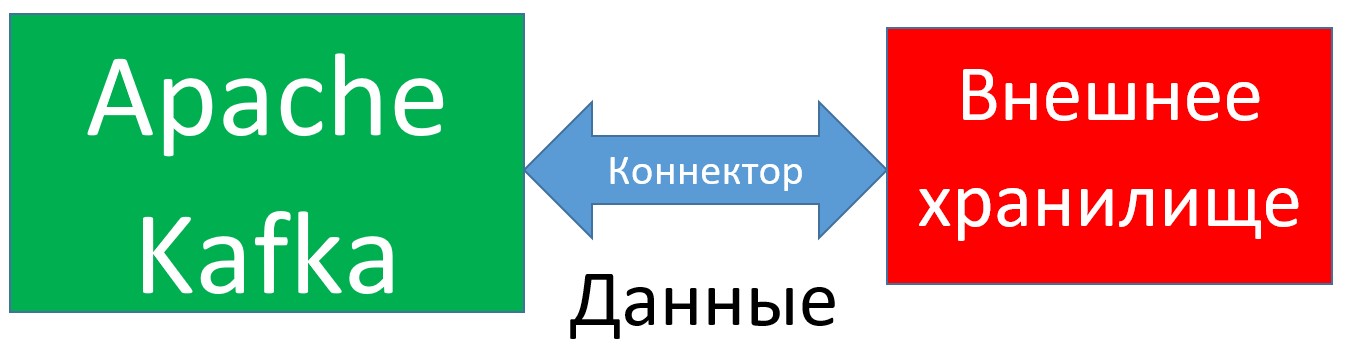
Плагины-коннекторы — это исполняемые библиотеки утилиты Kafka Connect, отвечающие за перемещение данных между брокером Kafka и каким-либо Big Data хранилищем (например, Amazon AWS S3, Elasticsearch и т.д.) [1].
Особенности работы утилиты Kafka Connect мы подробнее рассмотрим далее.
Утилита Kafka Connect
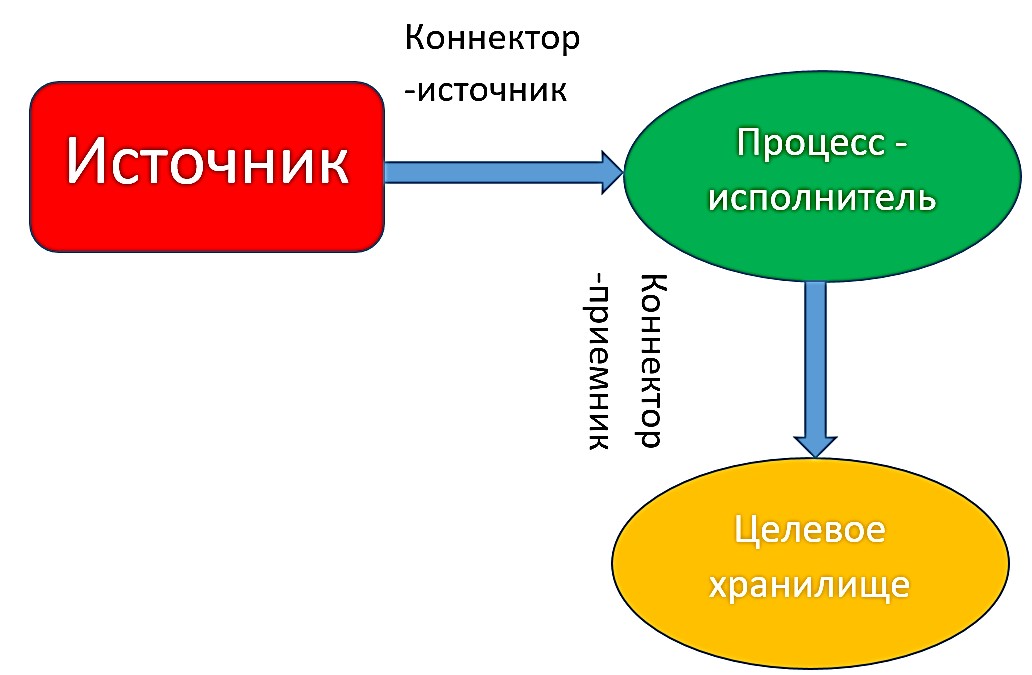
Kafka Connect — это утилита брокера сообщений Apache Kafka, которая отвечает за перемещение данных между Kafka и другими хранилищами больших данных. Кафка Коннект выполняется в виде кластера процессов-исполнителей (worker processes). На каждом процессе-исполнителе устанавливаются коннекторы, которые запускают задачи (tasks) для параллельного перемещения больших объемов данных и эффективного использования доступных ресурсов рабочих узлов. Задачам коннектора-источника необходимо прочитывать данные из системы-источника и передавать эти данные процессам-исполнителям. Задачи коннектора-приемника получают данные от процессов-исполнителей и записывают их в целевую информационную систему (хранилище) [1].
Кафка Коннект не требует дополнительной установки. Она находится в том же пакете, что что и Apache Kafka. Запуск Кафка Коннект происходит командной строке через файл connect-distributed.bat:
bin/connect-distributed.bat config/connect-distributed.properties
Рассмотрим пример подключения Кафка Коннект к хранилищу Amazon AWS S3 для загрузки данных из корзины (bucket) в топики (topic) Apache Kafka. Для этого необходимо прежде всего прописать учетные данные (открытый и закрытый ключи) в следующем формате:
aws_access_key_id = AKIAIOSFODNN7EXAMPLE aws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Далее через Strimzi (менеджер пакетов для платформы развертывания Kubernetes) необходимо настроить Docker-файл для коннектора S3:
FROM strimzi/kafka:0.16.1-kafka-2.4.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001
Имея настроенный Docker-образ можно развернуть Кафка Коннект путем создания следующего ресурса в Kubernetes (платформа для развертывания веб-приложений):
apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaConnect metadata: name: my-connect-cluster spec: image: docker.io/scholzj/kafka:camel-kafka-2.4.0 replicas: 3 bootstrapServers: my-cluster-kafka-bootstrap:9092 externalConfiguration: volumes: - name: aws-credentials secret: secretName: aws-credentials config: config.providers: file config.providers.file.class: org.apache.kafka.common.config.provider.FileConfigProvider key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: false value.converter.schemas.enable: false
После развертывания экземпляра Кафка Коннект необходимо создать коннектор S3 c помощью Strimzi:
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaConnector
metadata:
name: s3-connector
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: org.apache.camel.kafkaconnector.CamelSourceConnector
tasksMax: 1
config:
key.converter: org.apache.kafka.connect.storage.StringConverter
value.converter: org.apache.camel.kafkaconnector.converters.S3ObjectConverter
camel.source.kafka.topic: s3-topic
camel.source.url: aws-s3://camel-connector-test?autocloseBody=false
camel.source.maxPollDuration: 10000
camel.component.aws-s3.configuration.access-key: ${file:/opt/kafka/external-configuration/aws-credentials/aws-credentials.properties:aws_access_key_id}
camel.component.aws-s3.configuration.secret-key: ${file:/opt/kafka/external-configuration/aws-credentials/aws-credentials.properties:aws_secret_access_key}
camel.component.aws-s3.configuration.region: US_EAST_1
Теперь Кафка Коннект готова для загрузки данных из хранилища Amazon AWS S3 в брокер Apache Kafka [2].
Kafka Connect по умолчанию включает большинство готовых коннекторов для интеграции с наиболее популярными хранилищами Big Data (HDFS, Cassandra, Amazon S3, Elasticsearch и пр.), которые требуется только настроить для дальнейшего использования. Однако, если необходимо, можно создать собственный коннектор, например, для интеграции с уникальной системой, применяемой в вашем случае.
Таким образом, благодаря утилите Kafka Connect у брокера Apache Kafka есть возможность загрузки данных из любого хранилища больших данных, включая также облачные хранилища (Amazon AWS, Drophbox, ICloud). Благодаря этому Apache Kafka является универсальным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот фреймворк в задачах Data Science и разработке распределенных приложений. В следующей статье мы рассмотрим движок Apache Kafka KSQL.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Kafka Streams для разработчиков
- Интеграция Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных
- https://habr.com/ru/company/redhatrussia/blog/508056/

