В этой статье рассмотрим основные элементы зеркального копирования в распределенной среде Kafka-кластеров, обеспечивающих высокую отказоустойчивость данных. Узнайте, как работает этот механизм и почему он эффективен независимо от структуры данных в Apache Kafka.
Принцип работы зеркального копирования в распределенной среде Apache Kafka
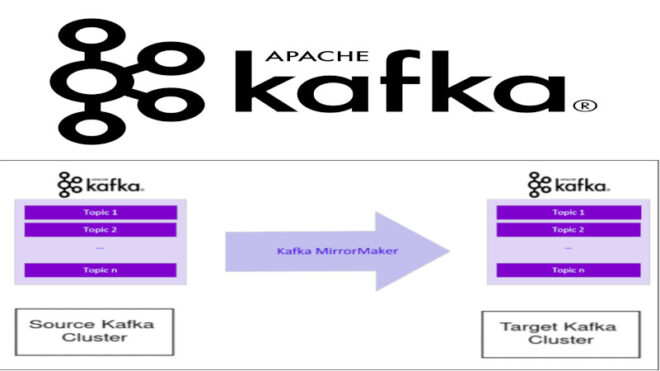
Зеркальное копирование (replication) является ключевым механизмом для обеспечения отказоустойчивости данных в Apache Kafka. Оно позволяет копировать данные из одной или нескольких тем Kafka на другой Kafka-брокер, создавая тем самым реплику (копию) исходных данных. Каждый Kafka-брокер в кластере может иметь несколько реплик, что позволяет распределять данные по различным узлам и обеспечивать высокую доступность и надежность кластера. В случае, если один из брокеров выходит из строя или теряет связь с кластером, другие брокеры могут продолжать обслуживать запросы клиентов, используя свои реплики данных. Это позволяет уменьшить риск потери данных и обеспечить непрерывную работу приложений, использующих Apache Kafka.
Функциональность утилиты Mirror Maker в Apache Kafka
Утилита Mirror Maker в Apache Kafka предназначена для реализации зеркального копирования данных между кластерами. Эта утилита состоит из группы потребителей (consumer), которые считывают данные из исходного кластера Kafka и производителя (producer), который отправляет данные на целевой кластер. Потребители в Mirror Maker объединены в группу и читают данные из выбранных тем. Для каждого потребителя запускается поток выполнения, который считывает данные из нужных топиков и разделов. После этого данные отправляются на целевой кластер с помощью производителя. Этот механизм позволяет обеспечить высокую отказоустойчивость данных и обеспечить непрерывность работы приложений, использующих Apache Kafka. Для обеспечения актуальности данных, потребители в утилите Mirror Maker в Apache Kafka отправляют продюсеру уведомления о необходимости передачи информации каждые 60 секунд. После этого потребители обращаются к исходному кластеру Kafka для фиксации смещения этих данных. Процесс начинается с формирования списка топиков с данными, которые нужно скопировать из исходного кластера на целевой кластер. Для этого можно использовать пример кода, который переименовывает топики в процессе копирования, а также позволяет выбирать только необходимые топики для копирования на целевой кластер [1]:
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import kafka.consumer.BaseConsumerRecord;
import kafka.tools.MirrorMaker;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.ProducerRecord;
public class RenameTopicHandler implements MirrorMaker.MirrorMakerMessageHandler {
private final HashMap<String, String> topicMap = new HashMap<String, String>();
public RenameTopicHandler(String topicList) {
String[] topicAssignments = topicList.split(";");
for (String topicAssignment : topicAssignments) {
String[] topicsArray = topicAssignment.split(",");
if (topicsArray.length == 2) {
topicMap.put(topicsArray[0], topicsArray[1]);
}
}
}
public List<ProducerRecord<byte[], byte[]>> handle(BaseConsumerRecord record) {
String targetTopic = null;
if (topicMap.containsKey(record.topic())) {
targetTopic = topicMap.get(record.topic());
} else {
targetTopic = record.topic();
}
Long timestamp = record.timestamp() == ConsumerRecord.NO_TIMESTAMP ? null : record.timestamp();
return Collections.singletonList(new ProducerRecord<byte[], byte[]>(targetTopic, null, timestamp, record.key(), record.value(), record.headers()));
}
}
Данный код представляет собой класс RenameTopicHandler, который реализует интерфейс MirrorMakerMessageHandler и отвечает за обработку сообщений, которые были считаны из топиков исходного кластера. Класс имеет поле topicMap, которое представляет собой хэш-таблицу, в которой ключом является имя топика на исходном кластере, а значением — имя топика на целевом кластере. Конструктор класса принимает на вход строку topicList, которая содержит список топиков на исходном кластере и их соответствующих имен на целевом кластере. Для того, чтобы получить список топиков, строка topicList разбивается на отдельные ассоциации топиков с помощью метода split(), а затем каждая ассоциация разбивается на исходное и целевое имя топика с помощью метода split(","). Метод handle() принимает на вход сообщение из топика исходного кластера в виде объекта BaseConsumerRecord. Затем он определяет соответствующий целевой топик, используя хэш-таблицу topicMap, и создает объект ProducerRecord<byte[], byte[]>, который содержит данные сообщения, а также информацию о топике, времени создания сообщения и заголовках. Метод возвращает список из одного объекта ProducerRecord<byte[], byte[]>, который содержит информацию об обработанном сообщении.
Для правильного «отражения» данных при зеркальном копировании также важно сохранять полную структуру исходных данных. Вот пример кода, который обрабатывает сообщения для копирования на целевой кластер, сохраняя при этом их структуру [1]:
import java.util.Collections;
import java.util.List;
import kafka.consumer.BaseConsumerRecord;
import kafka.tools.MirrorMaker;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.record.RecordBatch;
public class ExactMessageHandler implements MirrorMaker.MirrorMakerMessageHandler {
public List<ProducerRecord<byte[], byte[]>> handle(BaseConsumerRecord record) {
Long timestamp = record.timestamp() == RecordBatch.NO_TIMESTAMP ? null : record.timestamp();
return Collections.singletonList(new ProducerRecord<byte[], byte[]>(record.topic(), record.partition(), timestamp, record.key(), record.value(), record.headers()));
}
}
Таким образом, используя механизм зеркального копирования, Apache Kafka обеспечивает высокую надежность и устойчивость при обмене и хранении больших потоков данных, делая ее полезным инструментом для специалистов в области анализа и обработки больших данных, от Data Scientist до разработчика распределенных приложений.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Администрирование кластера Arenadata Streaming Kafka
Источники
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных

